
实时语音活动检测:兼顾精度与计算量的平衡之道
内容提要
语音活动检测(VAD)用于识别语音的起止点,以节省带宽并提高语音识别精度。本文介绍了一种适用于计算受限设备的实时统计模型VAD,结合噪声估计,能够在低信噪比下有效区分语音与非语音区域。
关键要点
-
语音活动检测(VAD)用于识别语音的起止点,节省带宽并提高语音识别精度。
-
传统VAD方法包括基于双门限和基于统计模型的算法,后者在低信噪比下表现更好。
-
深度学习VAD算法精度高但计算量大,轻量级模型可能导致延迟。
-
本文介绍了一种实时统计模型VAD,结合噪声估计,适用于计算受限设备。
-
统计模型假设语音与非相干加性噪声混合,通过高斯统计模型进行判别。
-
VAD决策规则基于频带的似然比几何平均值,使用最大似然估计方法。
-
决策导向方法(DD)结合上一个决策结果来更新信噪比估计,减少偏差。
-
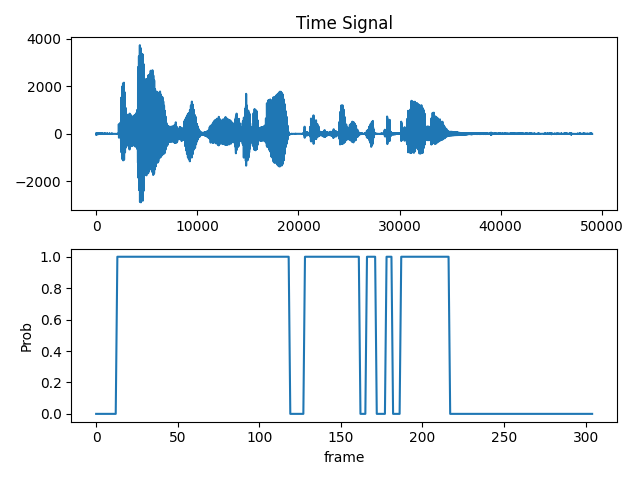
与WebRTC VAD比较,本文VAD在低信噪比情况下表现更佳,能够区分语音与非语音区域。
延伸解读
实时VAD的应用场景
实时语音活动检测(VAD)在语音识别和通信中具有重要意义,尤其是在带宽受限的环境下。本文介绍的统计模型VAD适用于计算能力有限的设备,能够有效提高语音识别的准确性,尤其是在低信噪比的情况下,适合移动设备和物联网应用。
与传统方法的比较
传统的双门限VAD方法在低信噪比环境下表现不佳,而深度学习VAD虽然精度高,但计算量大,可能导致延迟。本文提出的统计模型VAD通过结合噪声估计,能够在保持较低计算量的同时,提升在复杂环境下的语音检测能力,显示出更好的实用性。
决策导向方法的优势
决策导向(DD)方法通过结合先前的决策结果来更新信噪比估计,减少了偏差。这种方法不仅提高了VAD的准确性,还能更好地适应动态变化的环境,尤其在噪声干扰较大的情况下,能够有效提升语音与非语音的区分能力。
延伸问答
什么是语音活动检测(VAD)?
语音活动检测(VAD)是用于识别语音的起止点的算法,旨在节省带宽并提高语音识别精度。
传统的VAD方法有哪些?
传统的VAD方法包括基于双门限和基于统计模型的算法,后者在低信噪比下表现更好。
深度学习VAD算法的优缺点是什么?
深度学习VAD算法精度高,但计算量大,轻量级模型可能导致延迟。
本文介绍的实时统计模型VAD有什么特点?
本文介绍的实时统计模型VAD结合噪声估计,适用于计算受限设备,能够在低信噪比下有效区分语音与非语音区域。
VAD的决策规则是如何建立的?
VAD的决策规则基于频带的似然比几何平均值,使用最大似然估计方法进行判别。
与WebRTC VAD相比,本文的VAD表现如何?
在低信噪比情况下,本文的VAD表现更佳,能够更有效地区分语音与非语音区域,而WebRTC VAD则表现较差。
