在软件开发中,自动化安全工具如Dependabot存在告警疲劳和低信噪比的问题。专家Filippo Valsorda建议关闭Dependabot,使用基于静态分析的govulncheck,以提高安全性和效率。govulncheck通过精确的漏洞定位和调用图分析,能有效减少无用警报,帮助开发者关注真正的安全问题。
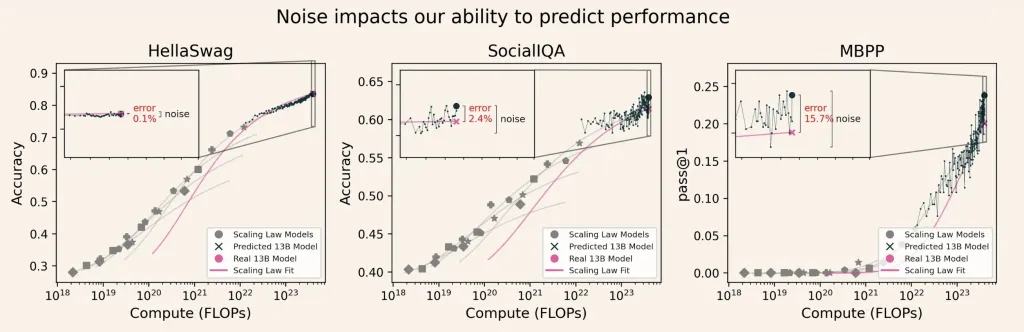
艾伦人工智能研究所提出了一种基于信号与噪声的框架,用于评估大语言模型(LLM)。该框架通过信噪比(SNR)提高评估的可靠性,帮助开发者做出更明智的决策。研究表明,高信噪比的基准测试能有效降低开发风险,提升模型性能评估的准确性。
服务水平指标(SLI)是可靠性工程的重要概念,反映消费者对服务的看法。本文介绍了SLI Compass,一个二维模型,用于评估现有SLI的信噪比、成本和复杂性,并指导改进方向。常见的SLI包括可用性、延迟、成功率和效率。通过将SLI映射到二维坐标系,可以更好地理解和优化服务质量。
该Python脚本遍历目录中的SAC文件,进行窄带滤波并计算信噪比(SNR)。信号窗口为2.5-5km/s,噪声窗口为信号后1000秒。仅保存SNR大于3的数据,并将结果写入CSV文件和生成可视化图表,使用8个CPU进行并行处理。
本研究提出了一种基于深度强化学习的在线学习框架,旨在解决6G网络中自适应波束切换的高频率、移动性和阻塞问题。该方法在信噪比、吞吐量和准确性方面显著优于传统方法。
本研究提出了一种新型深度学习MRI去噪方法SNRAware,通过模拟高质量合成数据集和利用定量噪声分布信息,显著提升了去噪性能和模型通用性。在多种成像序列中,该模型表现优异,尤其在实时心脏成像和灌注成像中,信噪比分别提升6.5倍和2.9倍。
本研究针对动态信道对基于联合源信道编码的语义通信系统的影响提出了解决方案。提出的SNR-EQ-JSCC架构通过将信噪比嵌入到注意力块以实现信道适应,并通过动态调整注意力分数,显著提高了图像传输的性能,尤其在感知指标上。实验结果表明,SNR-EQ-JSCC在高峰信噪比和计算复杂度上优于现有方法,具有较小的存储开销。
本研究探讨了无人机网络中的频谱感知问题,提出了一种基于联邦学习的FedSNR聚合方法,以提高信噪比下的模型准确性。实验结果表明,该方法在频谱共享和干扰管理方面优于传统方案,具有实际应用潜力。
本文探讨了卷积神经网络在无线电信号调制分类中的应用,比较了不同特征学习方法的有效性,展示了深度学习在低信噪比下的优势。研究提出了多种神经网络架构,强调了深度学习在无线通信信道估计和信号检测中的潜力,指出其在未来无线网络中的重要性和应用前景。
本研究探讨了联邦学习在上下行通信错误情况下的表现,并提出了新的收敛性分析。结果表明,为保持理想的收敛行为,需控制信噪比。此外,研究提出了DynamicFL框架,通过动态分配通信资源,提升模型性能,准确性提高了10%。
本文介绍了一种新的阴影去除方法,利用非配对数据和深度学习技术,显著提高了阴影去除效果。研究中采用了多种网络架构,如Mask-ShadowGAN、SP-Net和M-Net,并结合新的损失函数和注意力机制,优化了阴影处理能力。实验结果表明,该方法在多个数据集上表现优异,降低了错误率并提升了信噪比。
本研究提出了一种结合视觉和音频信号的深度学习模型,利用双向长短时记忆网络提升噪声环境下的语音增强质量。实验结果表明,该系统在语音清晰度和可懂度方面表现优异,尤其在低信噪比条件下显著降低了单词错误率。
本研究提出了一种新的方法,通过估计样本协方差中的共阵子空间来解决稀疏线性阵列定位源数超过传感器数的问题。基于深度神经网络的子空间表示学习方法在不同维度的学习计算中效率更高,并且在各种信噪比和源数量下超越了现有的处理方法,展现出更优的性能。
本文介绍了一种新型音频-视觉语音增强框架,利用个性化模型和神经编解码器从嘈杂信号中合成清晰语音。该框架通过深度学习和视觉信息提高语音质量,适用于多人对话和嘈杂环境,实验结果显示其在语音增强和噪音降低方面表现优异。
本文介绍了利用单片机内置的ADC和过采样技术提高分辨率的方法,过采样可以提高分辨率和信噪比,同时也可以提高ADC的信噪比。通过过采样和软件后处理,可以实现更高的分辨率。累加和抽取的方式可以在成本受限的情况下提高采样分辨率。
本文研究了高斯噪声下随机变量的最小均方误差(MMSE)估计,揭示了信噪比与输入分布的关系。提出了基于梯度下降的低秩矩阵估计框架,分析了高维推断中的正则化方法,并探讨了互信息与均方误差的关系。研究还涉及非线性观测信号的估计及其应用表现。
通过分析量子卷积神经网络(QCNNs),发现QCNNs利用量子数据嵌入物理系统参数,表现出高性能的量子相识别能力。QCNNs的汇集层选择有助于形成高性能决策边界的基函数。QCNN模型的泛化依赖于嵌入类型,基于有限测量次数的QCNN偏爱地面态嵌入和相关的物理信息模型。模拟结果为物理过程分类问题提供了启示。选择适当的地面态嵌入可用于流体动力学问题的QCNN。
探讨信噪比对音频生成对抗网络(GAN)性能的影响,以及针对 GAN 性能的三种不同评估方法,得出关于信噪比对 GAN 和 WaveGAN 的影响的有趣结果。
通过比较固定特征提取和端到端学习(CNN)方法,本研究提出并测试了一种用于对 Markush 结构进行分类的新方法。与固定特征方法相比,端到端方法表现显著更好,宏 F1 值达到 0.928(标准偏差 0.035),而固定特征方法为 0.701(标准偏差 0.052)。因实验性质,这些结果可进一步提高。结果表明,该提出的方法可以有效准确地过滤掉 Markush 结构,并能提高其应用于其他研究者的性能。
本文提出了一种具有选择性听觉机制的目标讲话者定位算法,通过给定目标讲话者的参考语音,消除干扰讲话者的语音,在经过长短期记忆网络提取过滤后的频谱图中的目标讲话者的位置。实验证实了该方法在不同尺度不变信噪比条件下相比现有算法的优越性。
完成下面两步后,将自动完成登录并继续当前操作。