
把笔记、微信读书、知乎装进 Obsidian:我基于llm-wiki知识中枢搭建实录
Mobility
·

守护所 — v5的诞生
Lifelog — A Mythology-Driven Devlog
·

微软Edge Copilot更新利用AI从所有标签页中提取信息
The Verge
·

如何发现和解锁视频中隐藏的数据
The New Stack
·

为什么您的代理无法读取企业文档——以及如何解决这个问题
Databricks
·



如何使用Python和多进程构建简历筛选系统
freeCodeCamp.org
·

工程副总裁Josh Clemm谈我们如何在Dash中使用知识图谱、MCP和DSPy
Dropbox Tech Blog
·
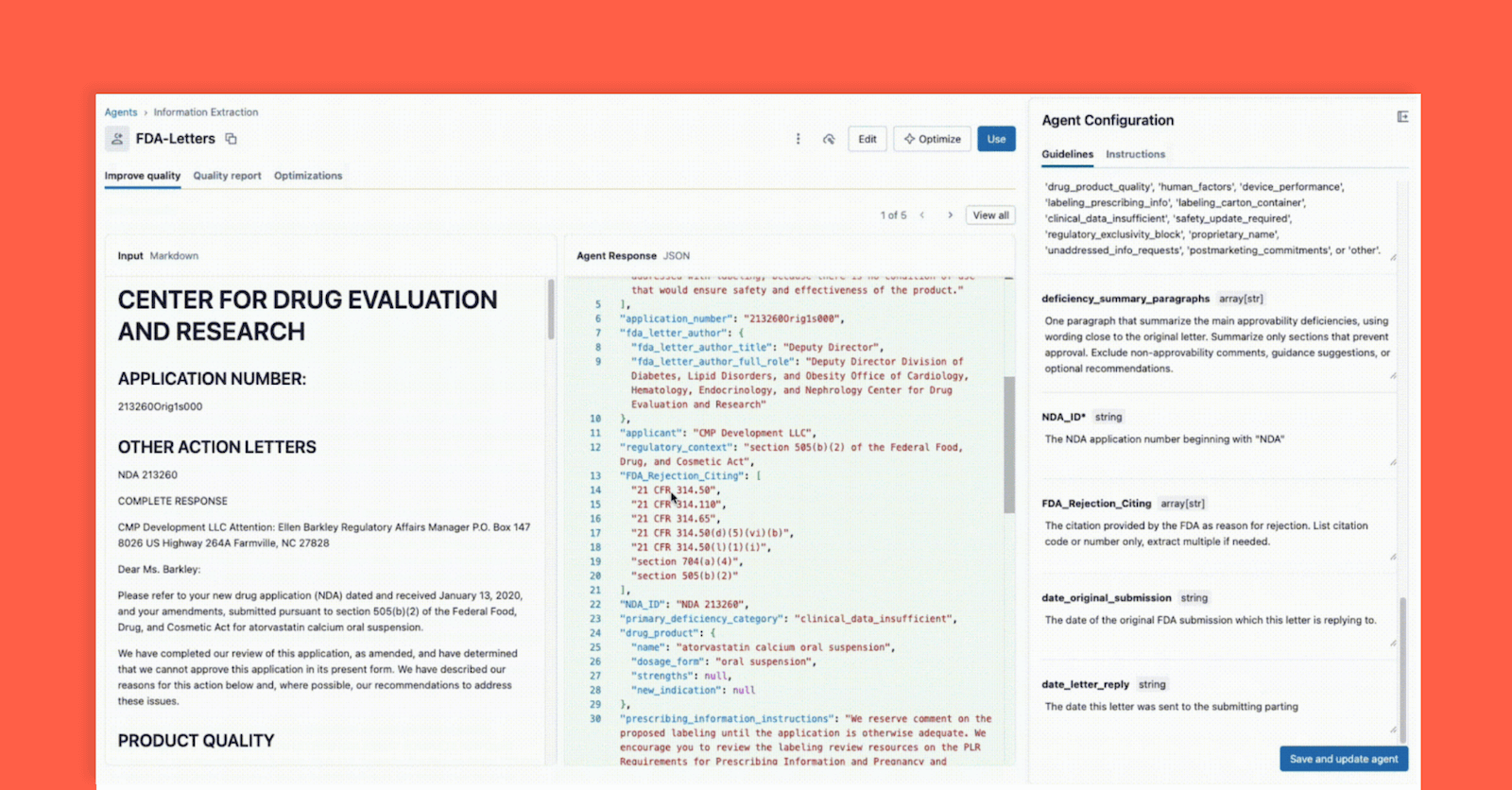
使用Databricks Agent Bricks构建合规风险助手(第一部分:信息提取)
Databricks
·

使用LangExtract和大型语言模型进行数据提取的初学者指南
KDnuggets
·
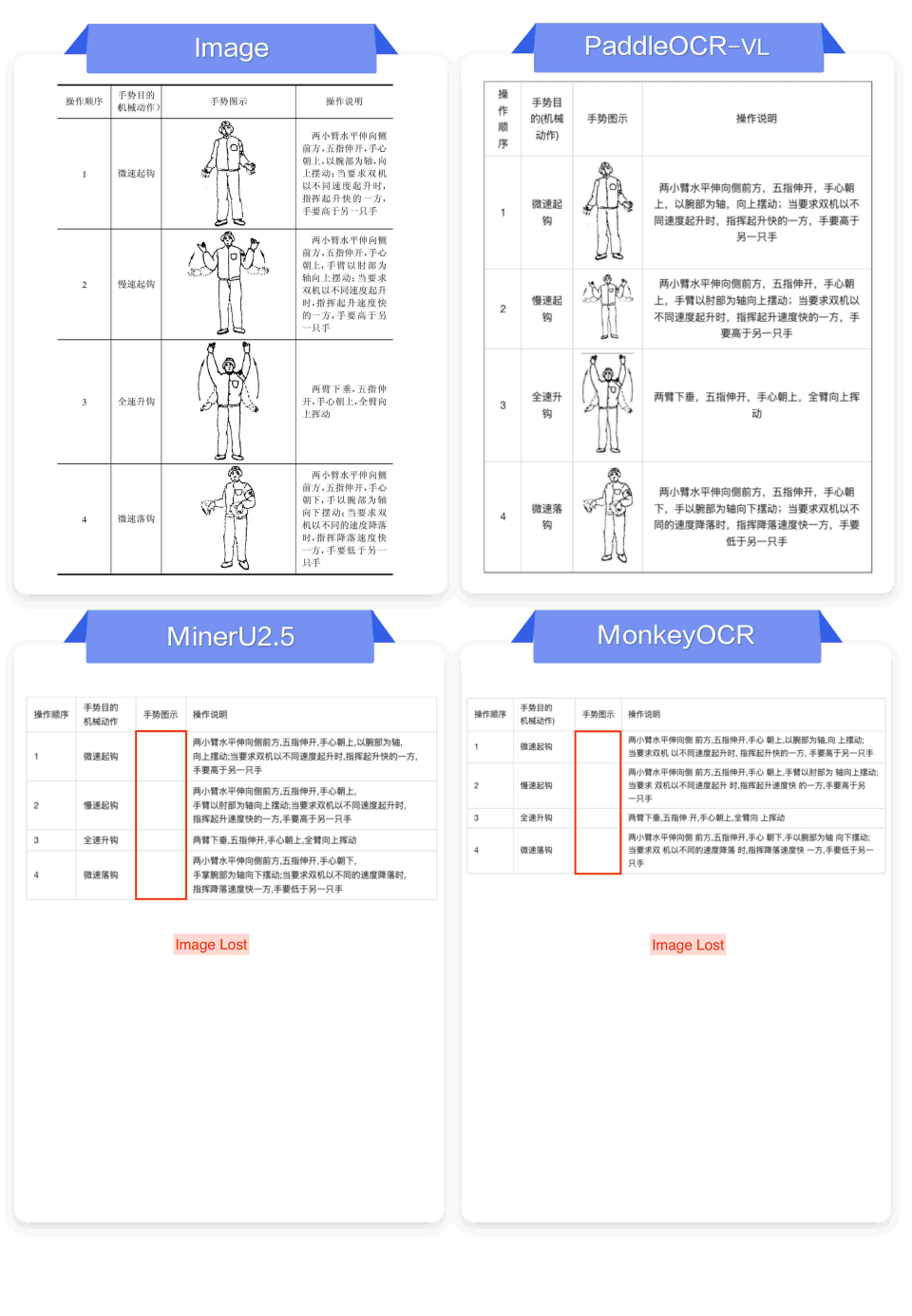

免费实用工具,好用的API接口
APISpace
·

通过自动化提示优化构建最先进的企业代理,成本降低90倍
Databricks
·
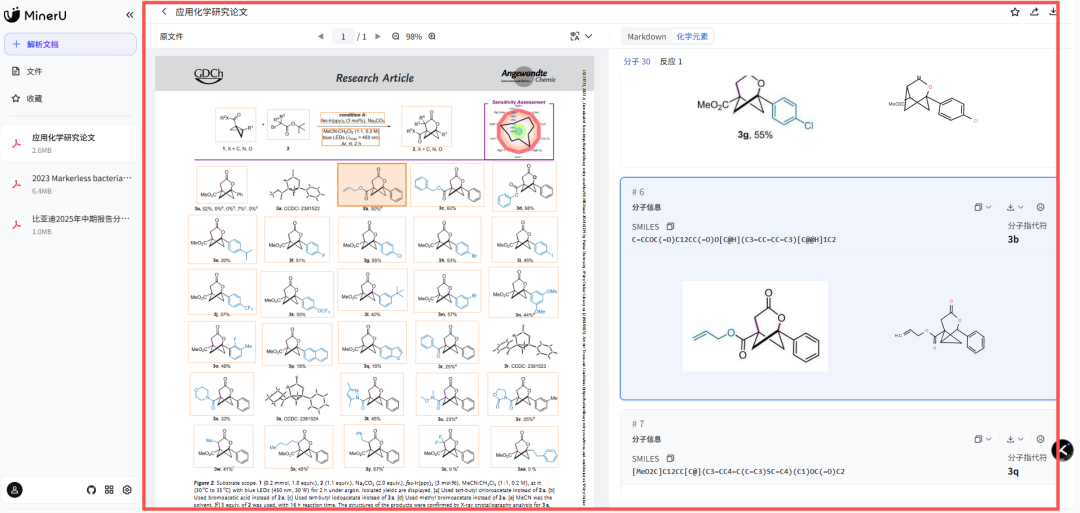
AI时代的文档解析神器:MinerU技术架构深度剖析与实战解码
dotNET跨平台
·

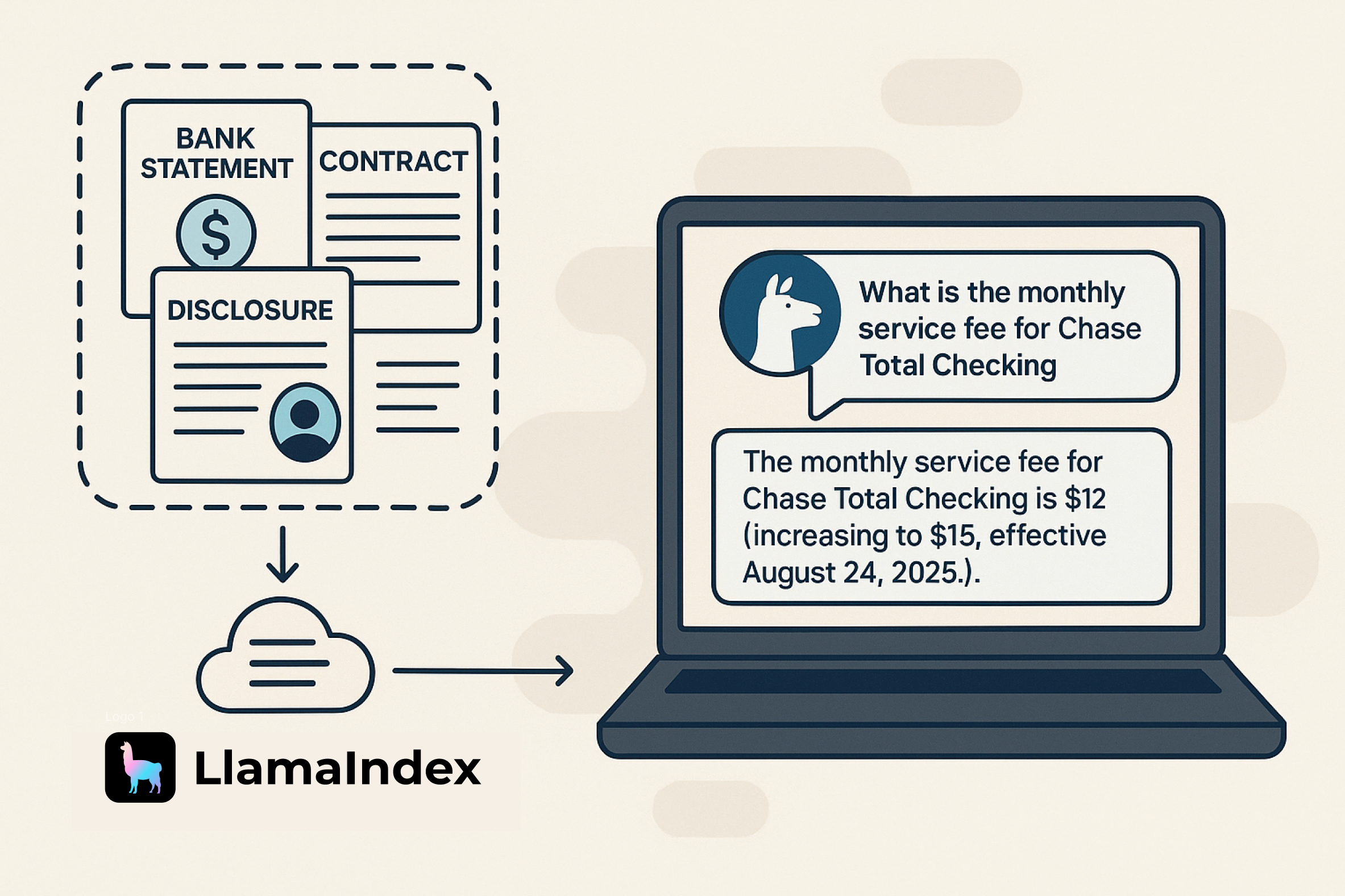
使用文档代理自动化工作流程:构建上下文感知AI的完整教程,基于LlamaCloud
Blog on LlamaIndex
·

如何利用命名实体识别(NER)从文本中提取洞察
freeCodeCamp.org
·
