
第1期:PaddleOCR-VL与主流模型对比:为何能在复杂场景中脱颖而出?
内容提要
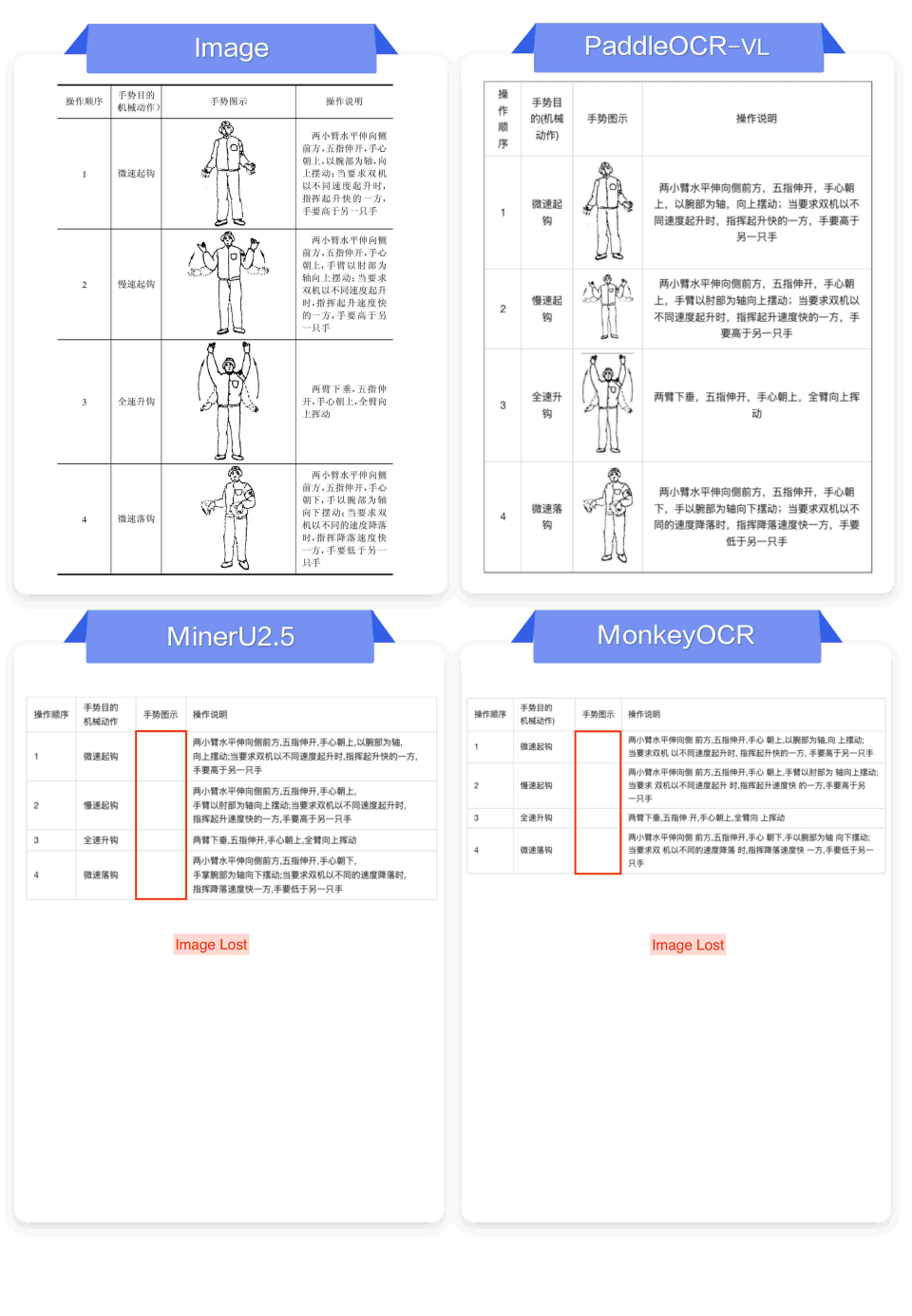
PaddleOCR-VL在文档智能领域表现优异,特别是在复杂版面、多语言识别、手写体、竖排文本、复杂表格与公式及图表信息提取方面,展现出高稳定性和准确性。其架构设计和丰富的训练数据使其在多项基准测试中超越竞争对手,成为文档解析的最佳选择。
关键要点
-
PaddleOCR-VL在复杂版面布局上表现稳定精准,能够准确检测页面中的所有元素和阅读顺序。
-
PaddleOCR-VL支持109种语言,能够精准区分不同语种,识别准确率高。
-
PaddleOCR-VL对手写体和竖排文本的识别能力强,能够处理工整或潦草的手写文字,并保持正确的阅读顺序。
-
PaddleOCR-VL在复杂表格和公式的识别上表现出色,能够准确还原表格结构和转换复杂公式为LaTeX代码。
-
PaddleOCR-VL能够理解并提取图表中的数据,实现从感知到认知的跨越。
-
PaddleOCR-VL的架构设计、丰富的训练数据和超轻量参数使其在文档解析领域中具备强大的竞争力。
延伸解读
复杂版面处理的优势
PaddleOCR-VL在复杂版面布局的处理上展现出色,能够准确识别文本、表格和图像等元素,避免了其他模型常见的布局错乱和内容幻觉问题。这使得其在需要高精度文档解析的场景中,成为更可靠的选择,尤其适合多栏和图文混排的文档。
多语言识别的可靠性
PaddleOCR-VL支持109种语言的识别,能够精准区分不同语种,避免了误识别的情况。这一特性使其在国际化业务中表现尤为突出,尤其适合需要处理多语言文档的企业和研究机构。
手写体与竖排文本的挑战
手写体和竖排文本一直是OCR技术的难点,而PaddleOCR-VL在这方面表现优异,能够处理工整或潦草的手写文字,并保持正确的阅读顺序。这一能力使其在文化遗产保护和古籍数字化等领域具有重要应用价值。
复杂表格与公式的理解能力
PaddleOCR-VL在复杂表格和公式的识别上展现出接近人类的理解能力,能够准确还原表格结构并转换复杂公式为LaTeX代码。这一特性对于需要处理大量数据和公式的学术研究和财务分析尤为重要,提升了文档解析的效率和准确性。
延伸问答
PaddleOCR-VL在复杂版面布局上的表现如何?
PaddleOCR-VL能够稳定、准确地检测页面中的所有元素和阅读顺序,避免布局错乱和内容幻觉。
PaddleOCR-VL支持多少种语言?
PaddleOCR-VL支持109种语言,能够精准区分不同语种。
PaddleOCR-VL如何处理手写体和竖排文本?
PaddleOCR-VL对中英文手写文字保持高识别率,并能正确处理中文竖排文本的阅读顺序。
PaddleOCR-VL在复杂表格和公式的识别上有什么优势?
PaddleOCR-VL能够准确还原表格结构和将复杂公式转换为LaTeX代码,表现出色。
PaddleOCR-VL如何提取图表中的数据?
PaddleOCR-VL能够理解并提取条形图、折线图、饼图等图表中的数据,生成对应的数据表格。
PaddleOCR-VL的架构设计有什么特点?
PaddleOCR-VL采用了“两阶段”模型设计,解耦了布局分析和元素识别,兼顾稳定性与精准度。
