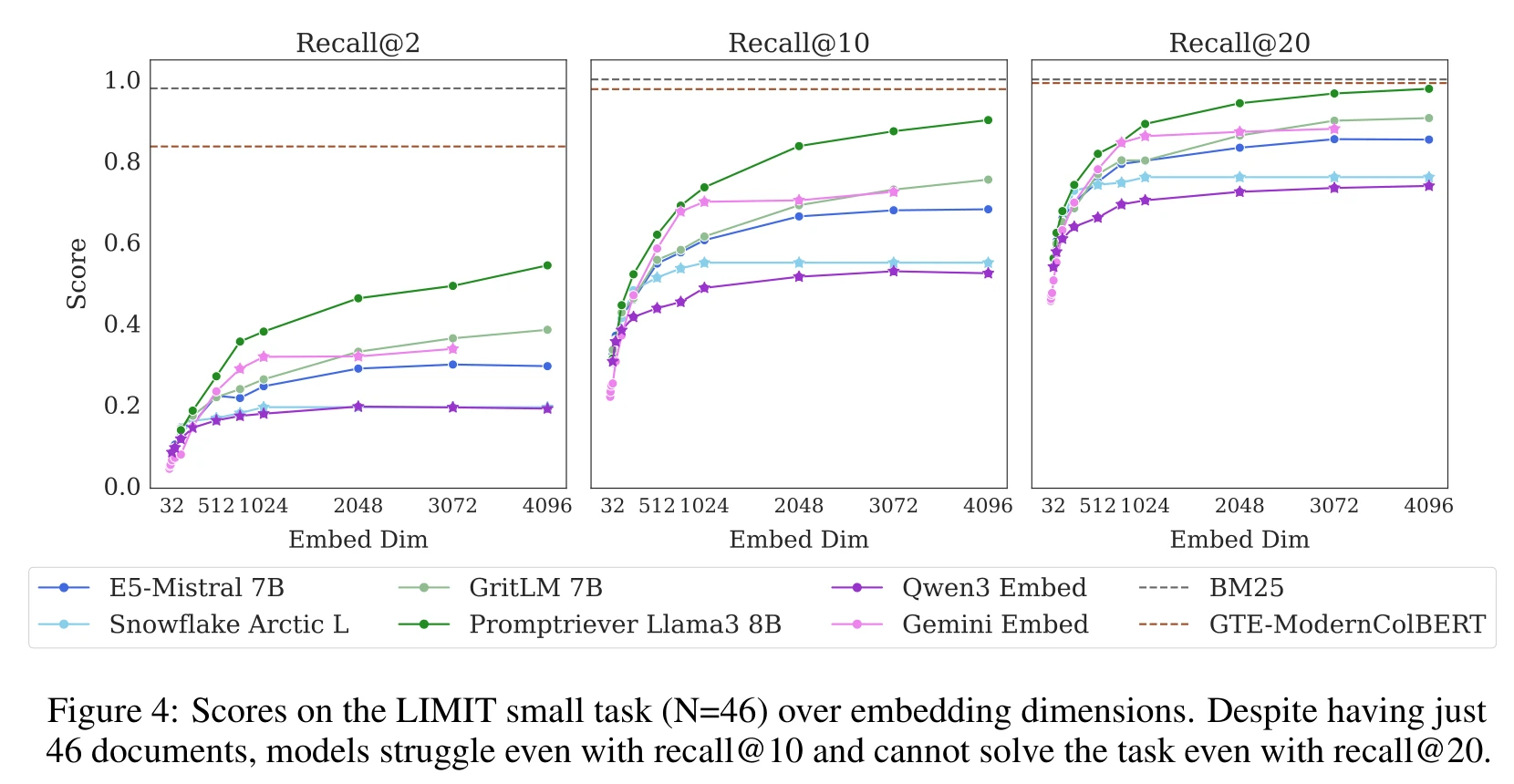
这篇文章探讨了向量检索的理论极限,指出在高维嵌入中,单向量模型无法有效表示所有检索结果。研究表明,查询复杂度增加时,单向量模型表现显著下降,无法满足高风险领域需求。文章建议结合BM25和密集检索,以弥补不足,并强调多向量模型和交叉编码器的重要性。
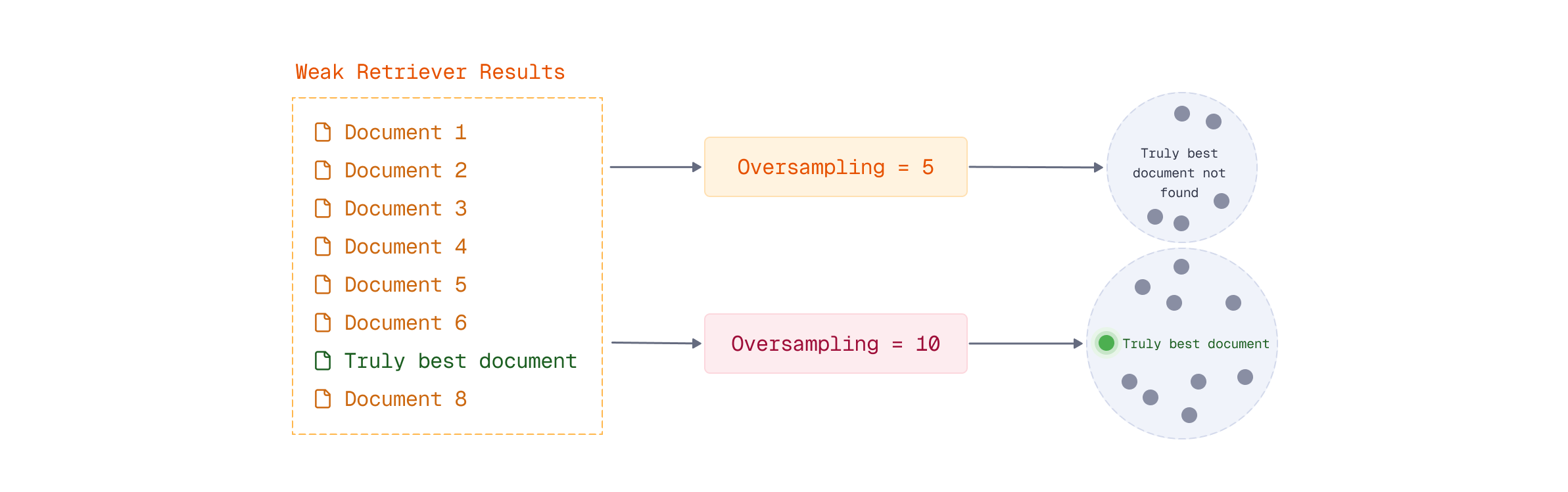
多阶段检索结合了快速单向量模型和高质量多向量模型的优点,通过预取阶段获取更多候选文档,并在重排序阶段使用ColBERT提高检索质量。过采样确保候选集足够大,以提高找到最佳文档的机会。Qdrant的通用查询API简化了多阶段检索的实现,适用于大规模文档集合。
完成下面两步后,将自动完成登录并继续当前操作。