
使用通用查询API的多阶段检索
内容提要
多阶段检索结合了快速单向量模型和高质量多向量模型的优点,通过预取阶段获取更多候选文档,并在重排序阶段使用ColBERT提高检索质量。过采样确保候选集足够大,以提高找到最佳文档的机会。Qdrant的通用查询API简化了多阶段检索的实现,适用于大规模文档集合。
关键要点
-
多阶段检索结合了快速单向量模型和高质量多向量模型的优点。
-
第一阶段使用快速单向量嵌入模型获取大量候选文档,第二阶段使用ColBERT对候选文档进行重排序。
-
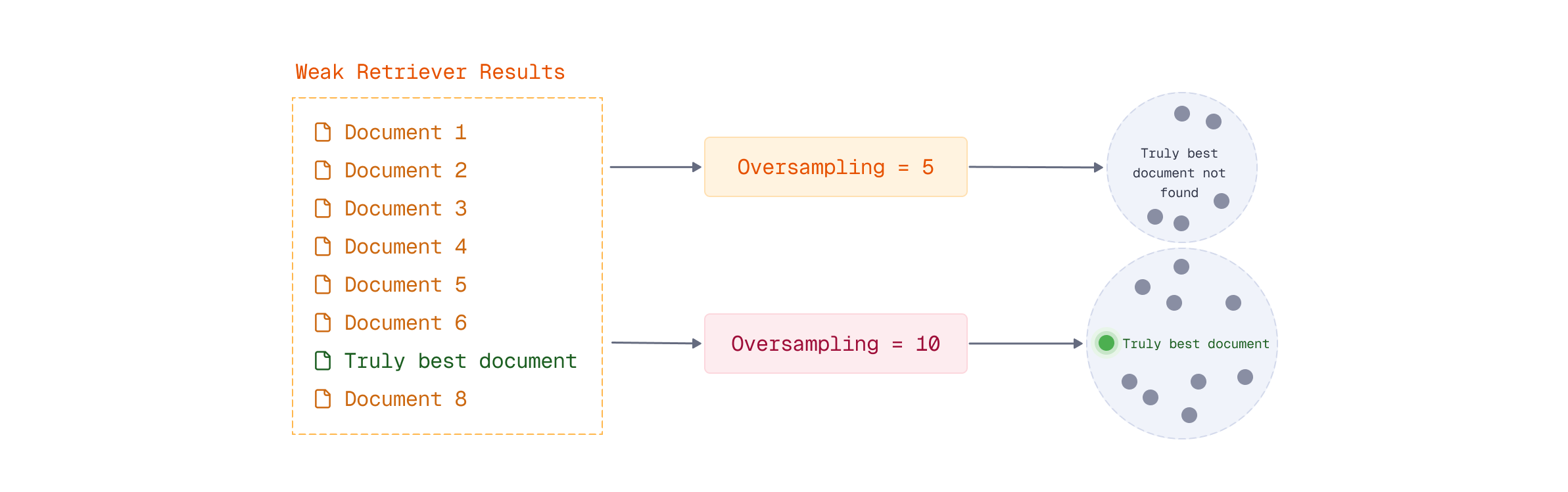
过采样确保在预取阶段获取的候选文档数量大于最终结果数量,以提高找到最佳文档的机会。
-
Qdrant的通用查询API简化了多阶段检索的实现,适用于大规模文档集合。
-
多阶段检索适用于大于10万文档的集合,能够在保持多向量质量的同时实现快速查询。
延伸解读
多阶段检索的优势
多阶段检索结合了快速和高质量模型的优点,能够在大规模文档集合中实现高效查询。通过第一阶段的快速单向量模型获取大量候选文档,第二阶段再利用ColBERT进行重排序,这种方法不仅提高了检索质量,还显著降低了计算成本。
过采样的重要性
在多阶段检索中,过采样是确保检索质量的关键。通过在预取阶段获取比最终结果更多的候选文档,可以增加找到最佳文档的机会。合理选择过采样因子,可以在提高检索质量和控制计算成本之间找到平衡。
适用场景与限制
多阶段检索特别适合于文档数量超过10万的场景,能够在保持高质量的同时实现快速查询。然而,对于小型文档集合或实时索引场景,使用单向量嵌入可能更为高效,因此在选择检索策略时需考虑具体情况。
延伸问答
什么是多阶段检索?
多阶段检索结合了快速单向量模型和高质量多向量模型的优点,通过预取和重排序阶段提高检索质量。
多阶段检索的两个主要阶段是什么?
第一阶段是使用快速单向量嵌入模型获取候选文档,第二阶段是使用ColBERT对候选文档进行重排序。
为什么在预取阶段需要过采样?
过采样确保获取的候选文档数量大于最终结果数量,以提高找到最佳文档的机会。
Qdrant的通用查询API如何简化多阶段检索的实现?
Qdrant的通用查询API通过预取参数简化了多阶段检索的实现,使得构建复杂的检索系统变得更加容易。
多阶段检索适合什么规模的文档集合?
多阶段检索适用于大于10万文档的集合,能够在保持多向量质量的同时实现快速查询。
多阶段检索的性能优势是什么?
多阶段检索通过减少多向量模型扫描的文档数量,提高了检索性能,显著降低了计算成本。
