
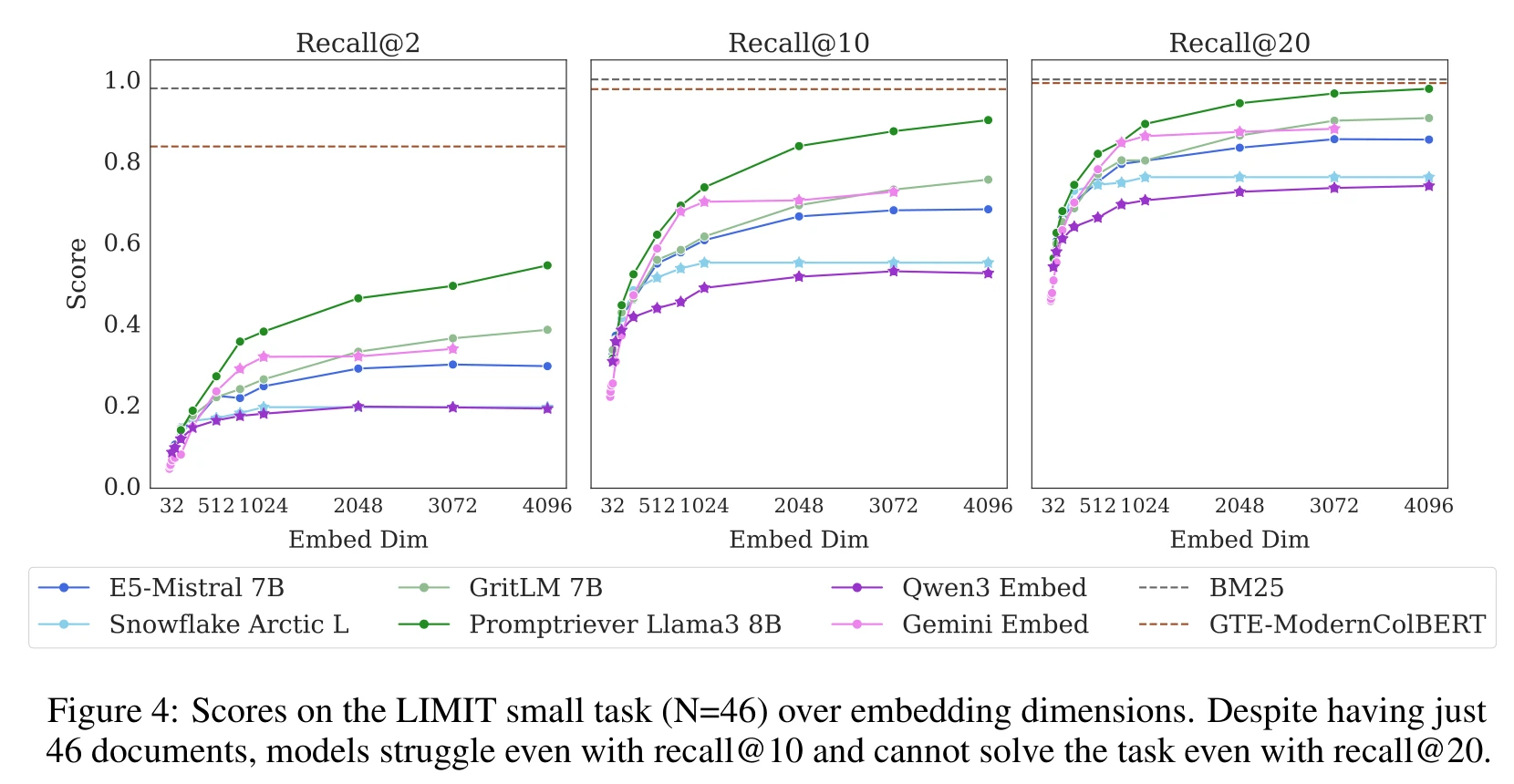
向量检索的理论极限
Finisky Garden
·
向量检索的理论天花板
Finisky Garden
·

复杂交互模型中的多向量
Qdrant - Vector Database
·
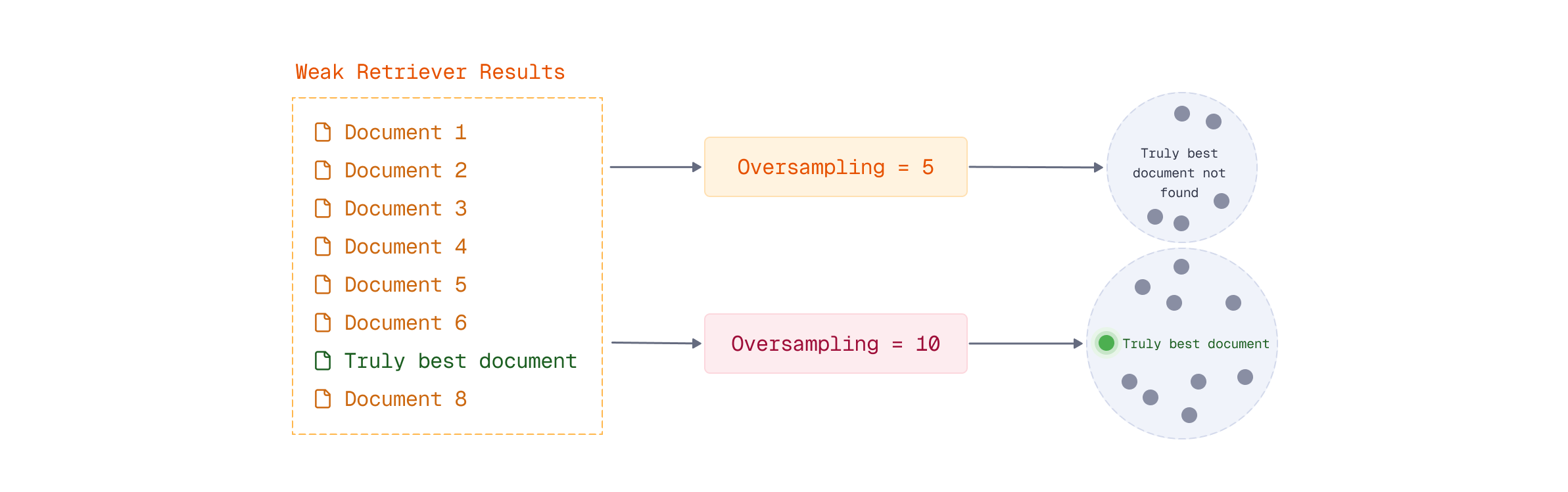
使用通用查询API的多阶段检索
Qdrant - Vector Database
·
