
向量检索的理论天花板
内容提要
向量检索在RAG系统中应用广泛,但存在理论限制。研究显示,单向量模型在复杂查询时维度不足,表现不佳。BM25在词汇匹配中表现优异,但在语义匹配上不如向量模型。为提高检索效果,结合BM25与向量检索或采用Cross-encoder等多向量模型是必要的。
关键要点
-
向量检索在RAG系统中应用广泛,但存在理论限制。
-
单向量模型在复杂查询时维度不足,表现不佳。
-
BM25在词汇匹配中表现优异,但在语义匹配上不如向量模型。
-
结合BM25与向量检索或采用Cross-encoder等多向量模型是必要的。
-
理论下界表明,向量维度需要足够大才能表示所有可能的top-k组合。
-
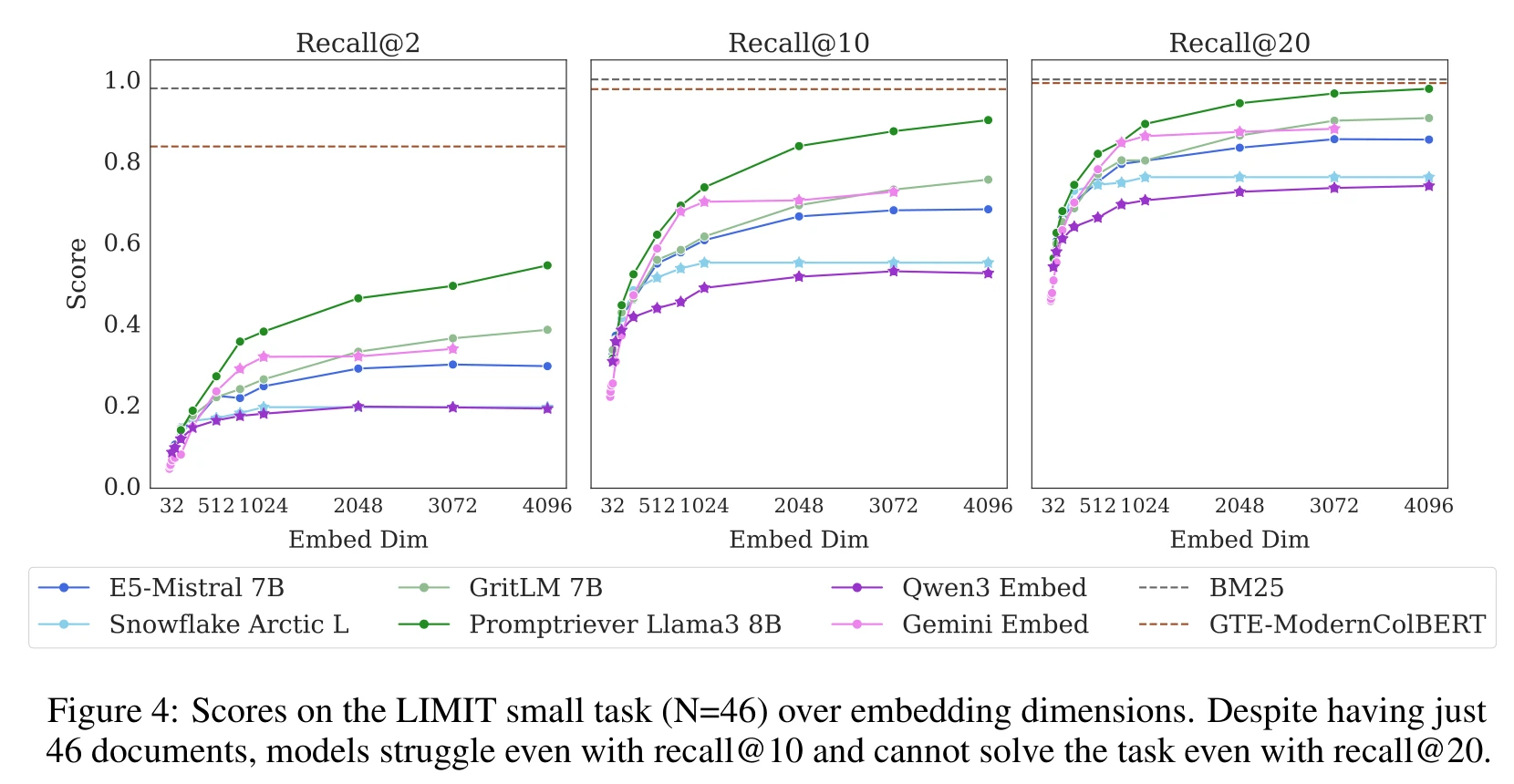
在LIMIT数据集上,单向量模型的表现远不如BM25,且在复杂查询中几乎完全失败。
-
Cross-encoder和多向量模型在表达能力上优于单向量模型,能够更好地处理复杂查询。
-
对于需要高覆盖率的关键场景,单纯依赖向量检索可能存在系统性盲区。
延伸解读
向量检索的局限性
向量检索在处理复杂查询时存在显著的局限性,尤其是当需要覆盖的top-k组合数量迅速增加时。单向量模型的维度不足以支持所有可能的组合,导致在实际应用中表现不佳。这一理论限制提醒开发者在设计RAG系统时,需考虑向量模型的表达能力与查询复杂度之间的关系。
BM25与向量检索的互补性
尽管BM25在词汇匹配中表现优异,但在语义匹配上却不及向量模型。两者的结合可以有效弥补各自的不足,尤其是在需要高覆盖率的场景中,如法律和医疗文档检索。开发者应重视这两种检索方法的互补性,以提升整体检索效果。
Cross-encoder的优势
Cross-encoder模型在处理复杂查询时表现出色,能够独立评分每个查询与文档对,克服了单向量模型的维度限制。尽管其在大规模检索中存在局限,但在需要高准确率的场景中,Cross-encoder提供了有效的解决方案,值得在实际应用中考虑。
延伸问答
向量检索在RAG系统中的应用有哪些限制?
向量检索在RAG系统中存在理论限制,单向量模型在复杂查询时维度不足,表现不佳。
BM25与向量检索的比较如何?
BM25在词汇匹配中表现优异,但在语义匹配上不如向量模型,因此两者的结合是必要的。
为什么单向量模型在复杂查询中表现不佳?
单向量模型的维度不足,无法表示所有可能的top-k组合,导致在复杂查询中几乎完全失败。
Cross-encoder模型的优势是什么?
Cross-encoder模型在表达能力上优于单向量模型,能够更好地处理复杂查询。
LIMIT数据集的构造目的是什么?
LIMIT数据集旨在验证向量模型在真实语言上的表现,设计了复杂的查询以覆盖所有可能的top-2组合。
向量检索在高覆盖率场景中的风险是什么?
在需要高覆盖率的关键场景中,单纯依赖向量检索可能存在系统性盲区,因此需要结合其他模型。
