
向量检索的理论极限
内容提要
这篇文章探讨了向量检索的理论极限,指出在高维嵌入中,单向量模型无法有效表示所有检索结果。研究表明,查询复杂度增加时,单向量模型表现显著下降,无法满足高风险领域需求。文章建议结合BM25和密集检索,以弥补不足,并强调多向量模型和交叉编码器的重要性。
关键要点
-
单向量模型在高维嵌入中无法有效表示所有检索结果。
-
查询复杂度增加时,单向量模型的表现显著下降,无法满足高风险领域的需求。
-
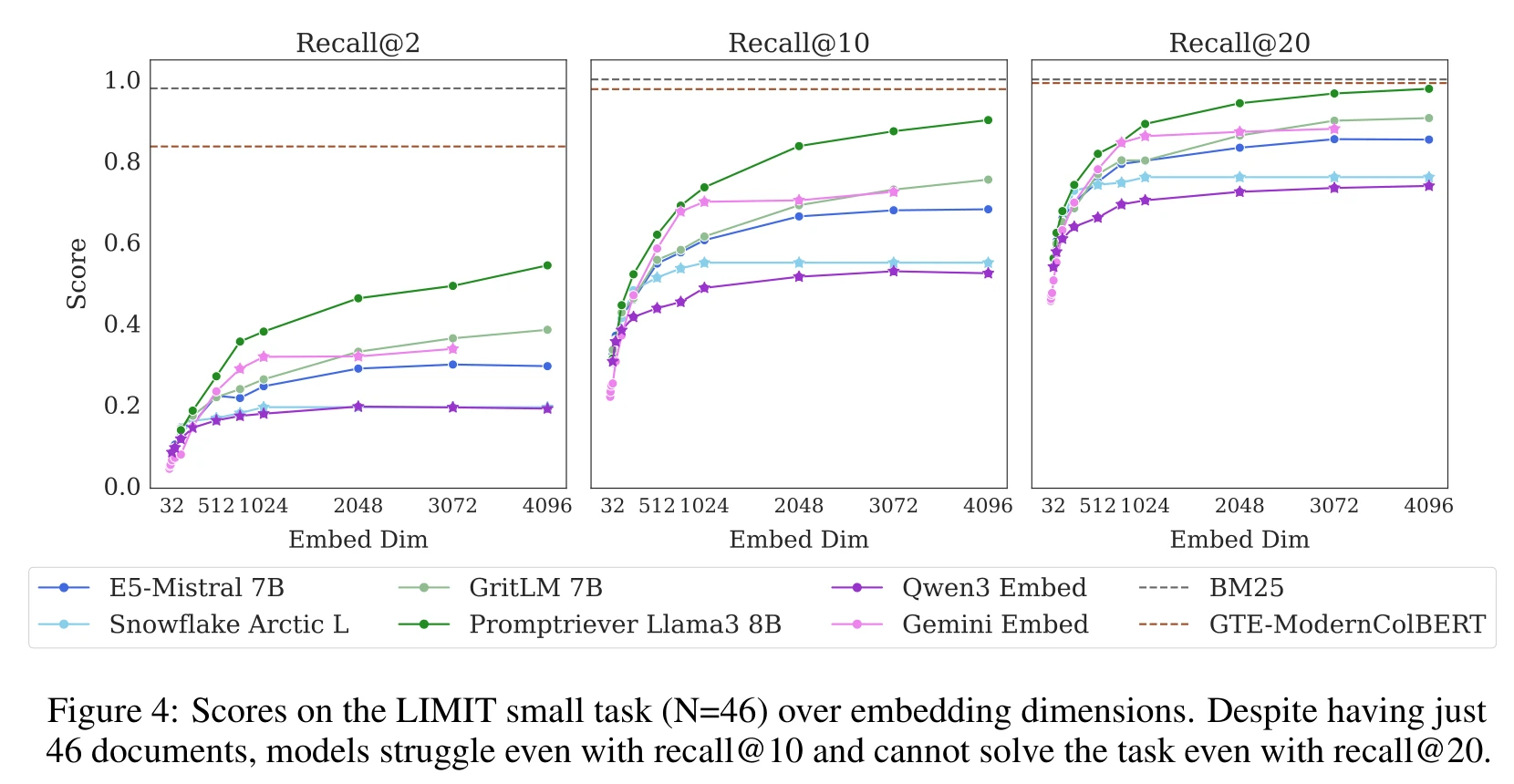
理论上,表示所有可能的top-k组合,嵌入维度d必须达到一定大小,当前模型的最大维度4096已接近理论下限。
-
在LIMIT数据集上,单向量模型的Recall@2表现极差,最高仅为5%。
-
BM25在LIMIT数据集上表现优异,但在语义匹配中表现脆弱,容易受到同义词替换的影响。
-
交叉编码器和多向量模型在检索任务中表现更好,能够克服单向量模型的限制。
-
对于高风险检索,单靠密集检索可能存在系统性盲点,交叉编码器重排序或多向量模型是必要的保障。
延伸解读
单向量模型的局限性
单向量模型在高维嵌入中面临显著的表现下降,尤其在查询复杂度增加时。这意味着在高风险领域,如法律和医疗,单靠单向量模型可能无法满足需求,必须考虑其他模型的结合使用。
BM25与密集检索的互补性
BM25在语义匹配中表现脆弱,容易受到同义词替换的影响,而密集检索则在低维空间中进行语义匹配。两者的互补性在高风险检索中显得尤为重要,单独依赖密集检索可能存在系统性盲点。
多向量模型的优势
多向量模型和交叉编码器在检索任务中表现优异,能够克服单向量模型的限制。随着查询复杂度的增加,采用这些更复杂的模型将成为提升检索效果的必要手段。
延伸问答
单向量模型在高维嵌入中有什么局限性?
单向量模型无法有效表示所有检索结果,尤其在查询复杂度增加时表现显著下降。
为什么BM25在LIMIT数据集上表现优异?
BM25在LIMIT数据集上表现优异是因为它进行的是纯词汇匹配,维度较高,但在语义匹配中表现脆弱。
交叉编码器和多向量模型如何克服单向量模型的限制?
交叉编码器和多向量模型通过提供更高的表达能力,能够更好地处理复杂查询和多样化的检索任务。
在高风险领域中,单靠密集检索有什么风险?
在高风险领域中,单靠密集检索可能存在系统性盲点,因此需要结合交叉编码器重排序或多向量模型作为保障。
LIMIT数据集的设计目的是什么?
LIMIT数据集的设计目的是测试模型在简单查询下的表现,确保覆盖所有可能的top-2组合。
当前模型的最大维度是多少?
当前模型的最大维度为4096,已接近理论下限。
