向量搜索并不等于找到正确答案。现代搜索系统结合双编码器和交叉编码器,前者用于快速召回候选文档,后者用于精确排序。有效的搜索系统需兼顾速度与准确性,以提升搜索质量。
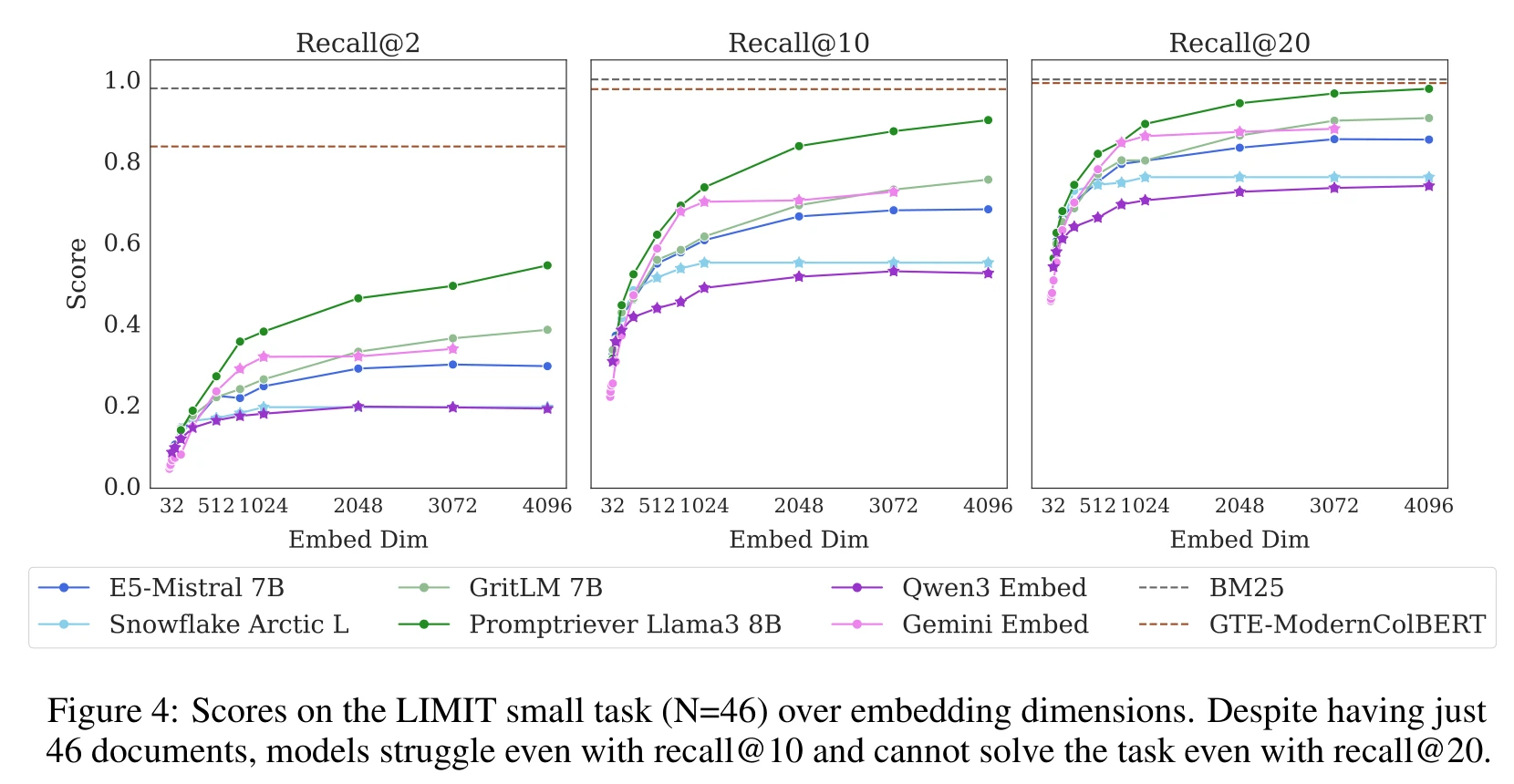
这篇文章探讨了向量检索的理论极限,指出在高维嵌入中,单向量模型无法有效表示所有检索结果。研究表明,查询复杂度增加时,单向量模型表现显著下降,无法满足高风险领域需求。文章建议结合BM25和密集检索,以弥补不足,并强调多向量模型和交叉编码器的重要性。
本研究提出了一种增强记忆的交叉编码器(CtrlCE),旨在解决个性化搜索中用户缺乏控制权的问题。该模型利用用户历史数据,允许用户控制个性化过程,从而提高搜索结果的相关性和多样性。研究表明,该方法在多个数据集上有效提升了个性化搜索的可控性。
在Qdrant的实习中,我负责将交叉编码器集成到FastEmbed库中,用于重新排序任务,增强了搜索应用的上下文感知能力。我设计了支持ONNX模型的类,优化了标记化和模型加载,成功实现了集成,为未来的搜索引擎和推荐系统提供了新可能。
AIxiv专栏介绍了排序模型中的双编码器和交叉编码器架构,以及以ColBERT为代表的延迟交互模型。ColBERT采用双编码器策略,提供高效的排序性能和精准的搜索排序结果。Infinity数据库提供了端到端的ColBERT方案,通过Tensor数据类型和Tensor Index技术优化计算性能。评测结果表明,ColBERT作为Reranker能够显著提升搜索结果质量。ColBERT及其延迟交互模型在RAG场景具有应用价值。
关键词搜索和语义搜索是提高搜索结果相关性的有效方法。传统重新排序依赖于历史用户交互数据,而交叉编码器是一种高级替代方法,能够评估新的、未见过的数据。交叉编码器通过解决深度文本分析中的限制,提高重新排序系统的性能。
本文介绍了一种基于交叉编码器的检索方法,利用CUR分解提高检索效率,特别是在k-NN查询中表现优越。研究表明,该方法在减少近似误差和提高检索率方面优于传统的BM25和双编码器方法。此外,提出的聚类嵌入学习(CEL)和协作相似度嵌入模型(CSE)在推荐系统中也显示出显著优势。
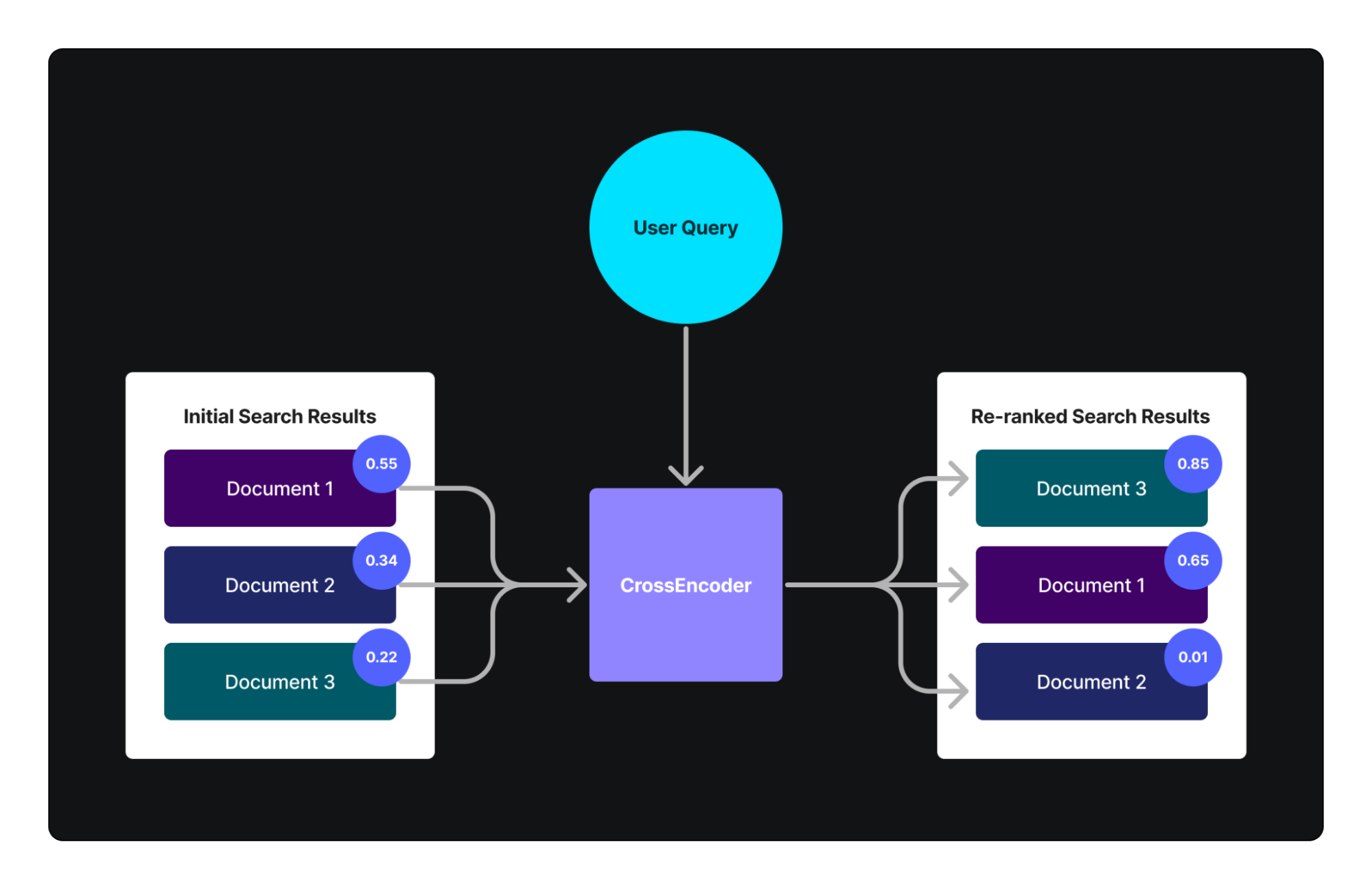
本文比较了双编码器和交叉编码器的差异,双编码器适合搜索,速度快且可扩展性强,交叉编码器适合分类和高精度排名,更准确。双编码器独立编码每个句子,将输入文本编码为固定长度向量,而交叉编码器同时对两个句子进行编码,能捕获句子之间的关系。在实践中,可以先使用双编码器减少候选数量,再使用交叉编码器获取最终结果。交叉编码器可用于语义相似性任务。通过两阶段检索和重新排序系统,可以在实践中使用双编码器和交叉编码器。
完成下面两步后,将自动完成登录并继续当前操作。