
提升向量搜索:使用PostgresML和LlamaIndex进行重新排序
原文英文,约1900词,阅读约需7分钟。
📝
内容提要
关键词搜索和语义搜索是提高搜索结果相关性的有效方法。传统重新排序依赖于历史用户交互数据,而交叉编码器是一种高级替代方法,能够评估新的、未见过的数据。交叉编码器通过解决深度文本分析中的限制,提高重新排序系统的性能。
🎯
关键要点
-
关键词搜索和语义搜索是提高搜索结果相关性的有效方法。
-
传统的重新排序依赖于历史用户交互数据,但在处理新内容时效果不佳。
-
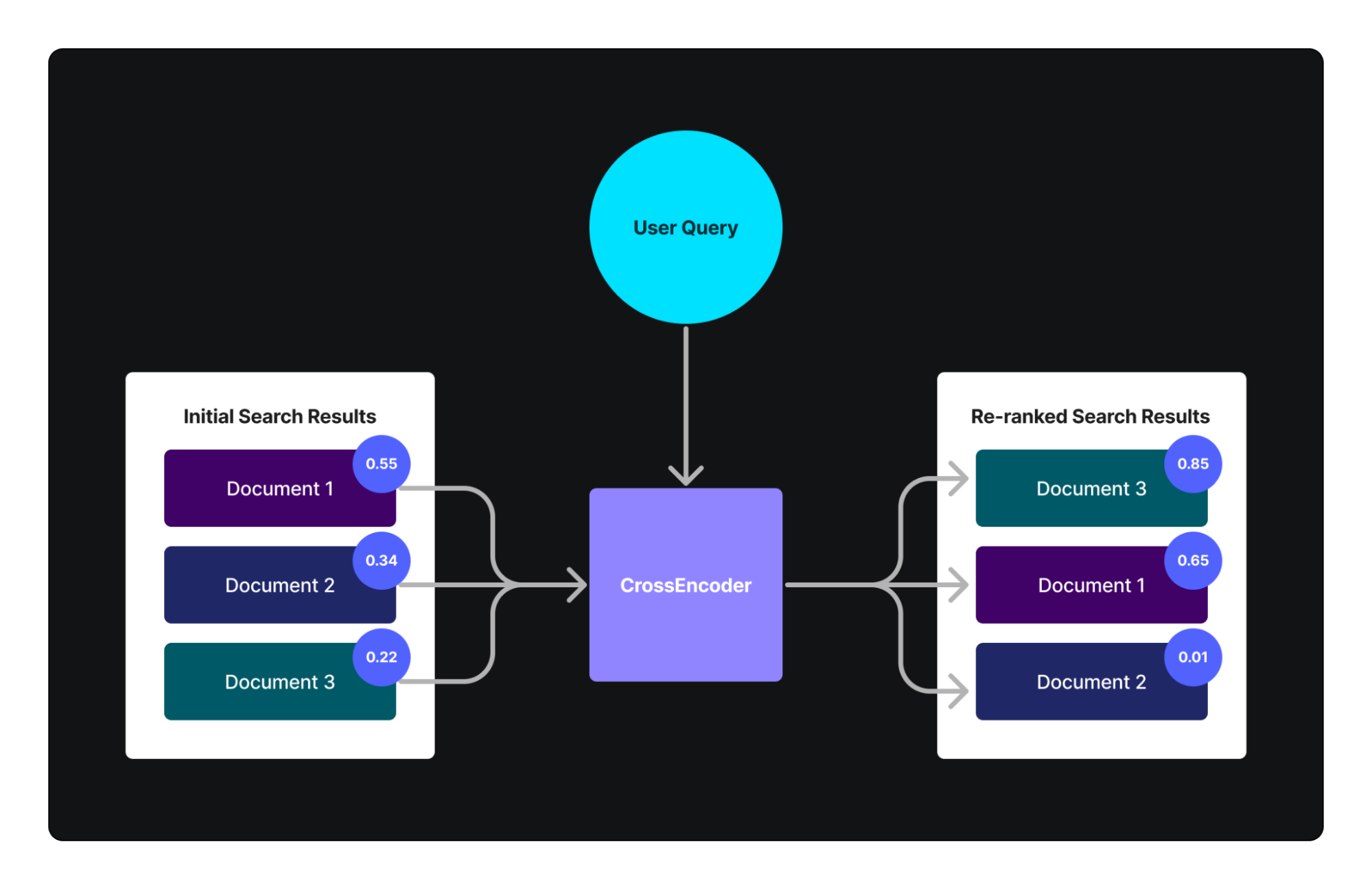
交叉编码器通过直接比较查询-结果对来评估相似性,是一种高级替代方法。
-
交叉编码器在处理新数据时表现出色,不需要大量用户交互数据进行微调。
-
交叉编码器可以增强传统重新排序系统的性能,特别是在处理新颖或特定内容时。
-
实现重新排序的示例使用LlamaIndex和PostgresML管理索引。
-
PostgresML管理索引处理文档的存储、分割、嵌入和查询。
-
使用交叉编码器进行重新排序可以显著提高搜索结果的相关性。
-
重新排序与交叉编码器结合使用可以在检索增强生成应用中提供更精确的答案。
❓
延伸问答
什么是关键词搜索和语义搜索,它们有什么区别?
关键词搜索通过精确匹配查询词与数据库内容,而语义搜索则利用自然语言处理和机器学习理解查询的上下文和意图。
传统的重新排序方法有什么局限性?
传统的重新排序依赖于历史用户交互数据,处理新内容时效果不佳,并且需要大量数据进行有效训练。
交叉编码器是如何提高搜索结果相关性的?
交叉编码器通过直接比较查询-结果对来评估相似性,特别擅长处理新数据,无需大量用户交互数据进行微调。
如何使用LlamaIndex和PostgresML进行重新排序?
可以通过创建PostgresML索引并使用交叉编码器进行重新排序,具体步骤包括安装依赖、加载文档和配置检索器。
交叉编码器在处理新数据时的表现如何?
交叉编码器在处理新、未见过的数据时表现出色,能够有效评估相似性而不依赖于大量用户交互数据。
重新排序与交叉编码器结合使用有什么好处?
结合使用可以增强传统重新排序系统的性能,提供更精确的答案,特别是在检索增强生成应用中。
🏷️
