本研究探讨了跨语言摘要中的语义一致性问题,提出了一种基于重新排序的方法和多标准评估协议,以促进不同语言间的语义相似多目标摘要。
本研究提出了增强型推荐模型ELMRec,解决了现有推荐系统在用户与项目高阶交互建模上的不足。通过增强词嵌入和引入重新排序方案,ELMRec在直接推荐和序列推荐中表现优于现有方法。
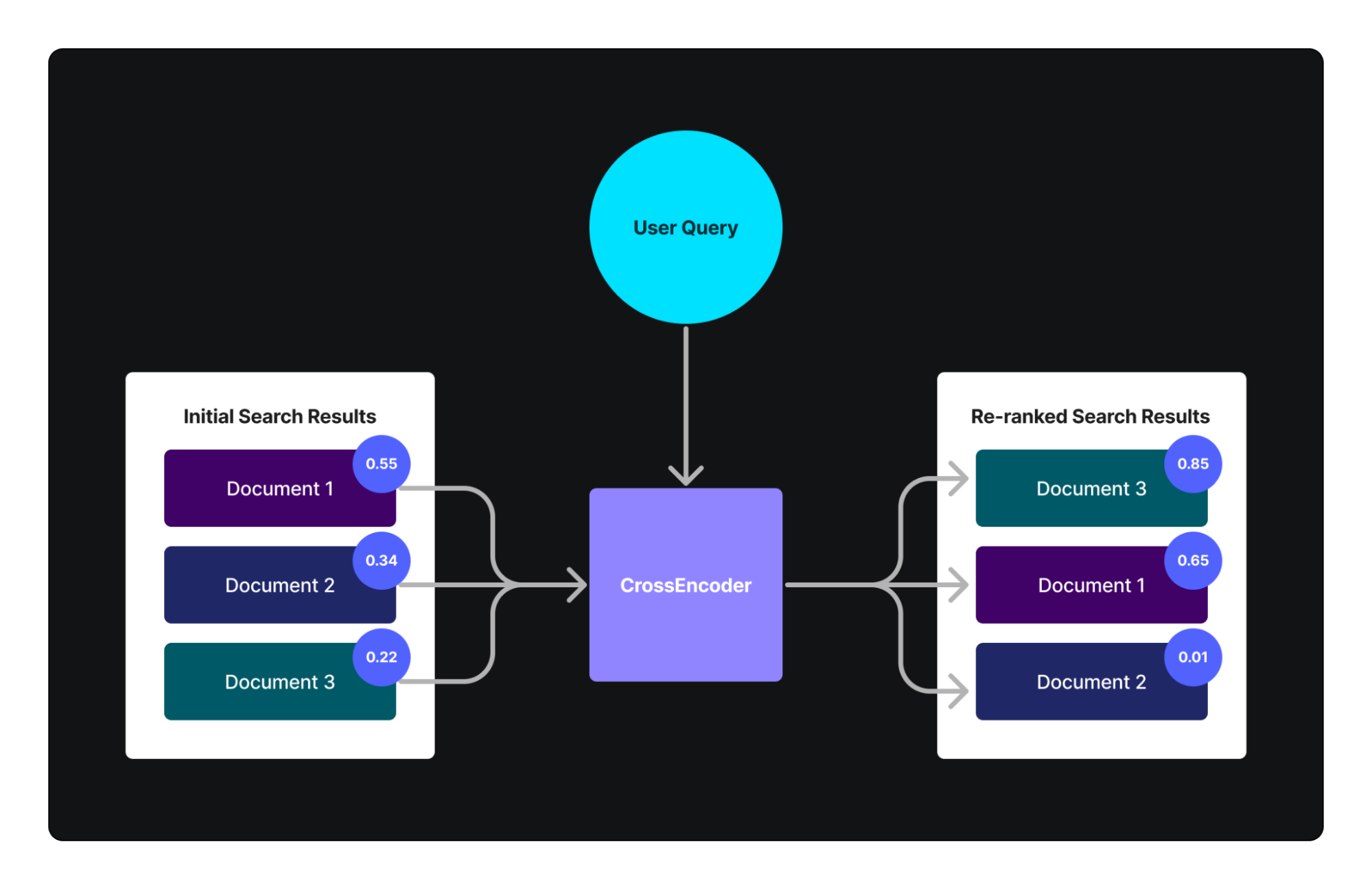
关键词搜索和语义搜索是提高搜索结果相关性的有效方法。传统重新排序依赖于历史用户交互数据,而交叉编码器是一种高级替代方法,能够评估新的、未见过的数据。交叉编码器通过解决深度文本分析中的限制,提高重新排序系统的性能。
本文探讨了多种高效的文档检索和重新排序方法,包括预训练的编码器-解码器模型、稀疏矩阵因子分解和ColBERTv2等。这些方法在提高检索速度和准确率方面表现优异,尤其是在低延迟环境下,较浅的变形器模型能显著提升性能。
本文介绍了ECT方法,通过从ChatGPT中学习评价模型并应用于强化学习和重新排序方法,以改善序列生成模型。实验结果表明,ECT在机器翻译、文本风格转换和摘要任务上取得了有效结果。
完成下面两步后,将自动完成登录并继续当前操作。