


提高GitHub Copilot中的令牌效率
Visual Studio Code - Code Editing. Redefined.
·

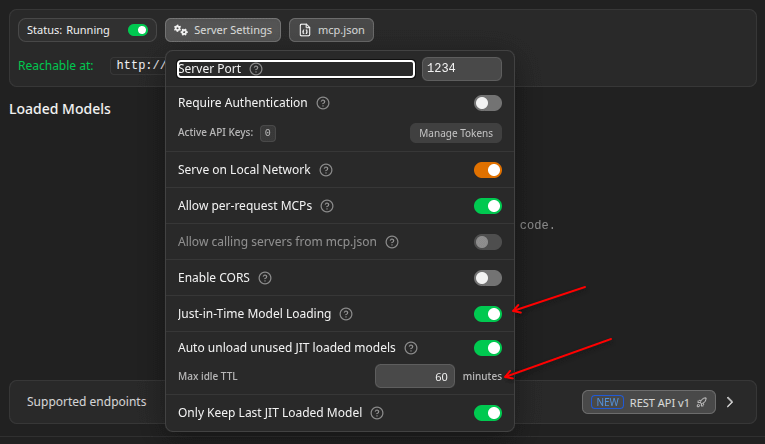
使用本地大型语言模型进行自主编程
Alex Ewerlöf Notes
·



Modular:为什么大语言模型推理需要一种新型路由器 - 第1部分
Modular Blog
·
检测平均时间是数据访问问题
Databricks
·

OpenAI推出GPT-5.5 Instant作为默认ChatGPT模型,承诺提供更准确的响应
The New Stack
·

通过WebSocket加速响应API中的智能工作流程
OpenAI
·

通往响应迅速的基于IntelliJ的IDE之路
The JetBrains Blog
·
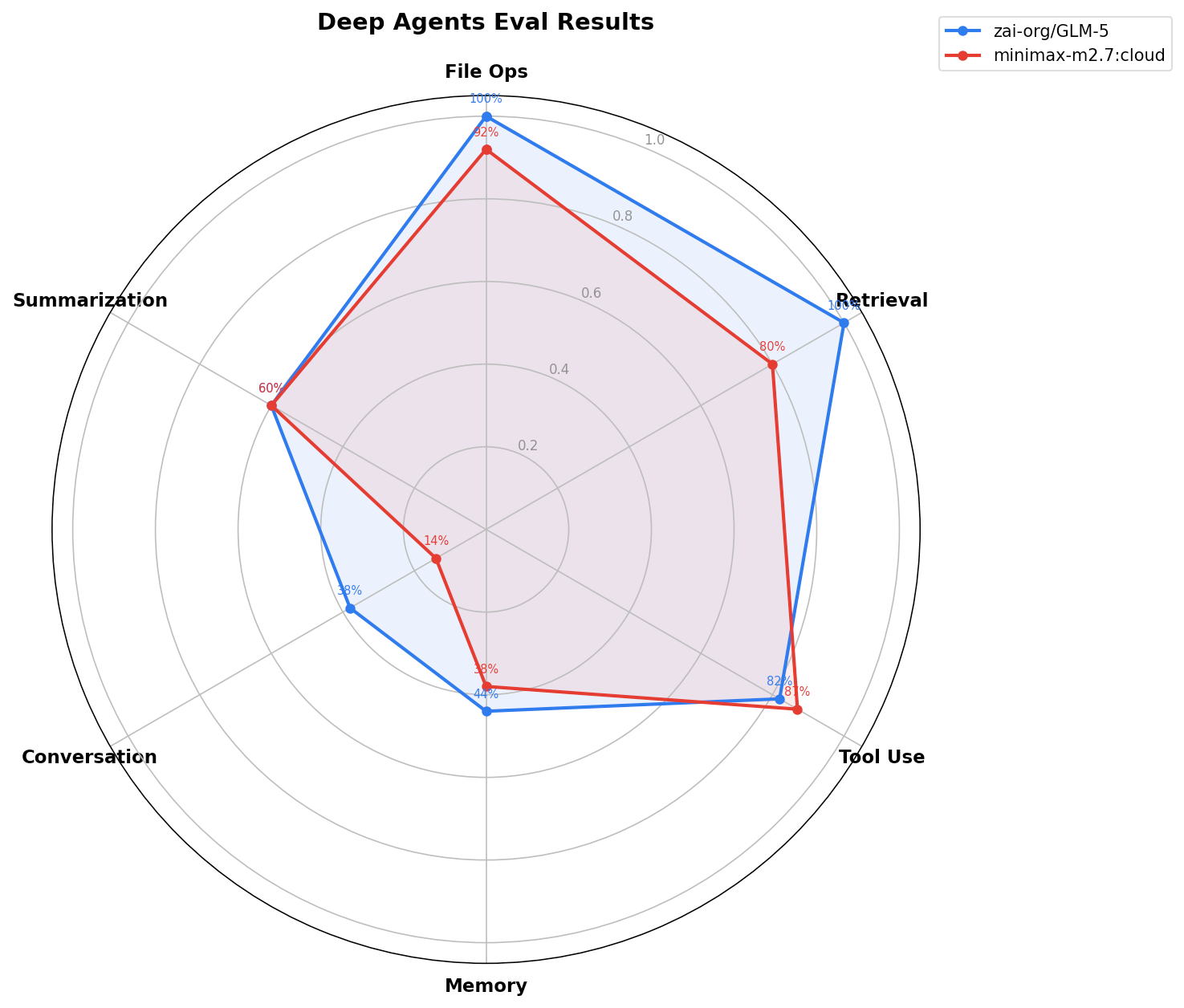
开放模型已跨越一个新阶段
LangChain Blog
·

TTFT的含义:首次令牌时间对您的大型语言模型应用程序的启示
Redis Blog
·

GPT-5.3 Instant 系统卡
OpenAI
·

使用Valkey加速应用程序的指南:缓存数据库查询和会话
Percona Database Performance Blog
·
