
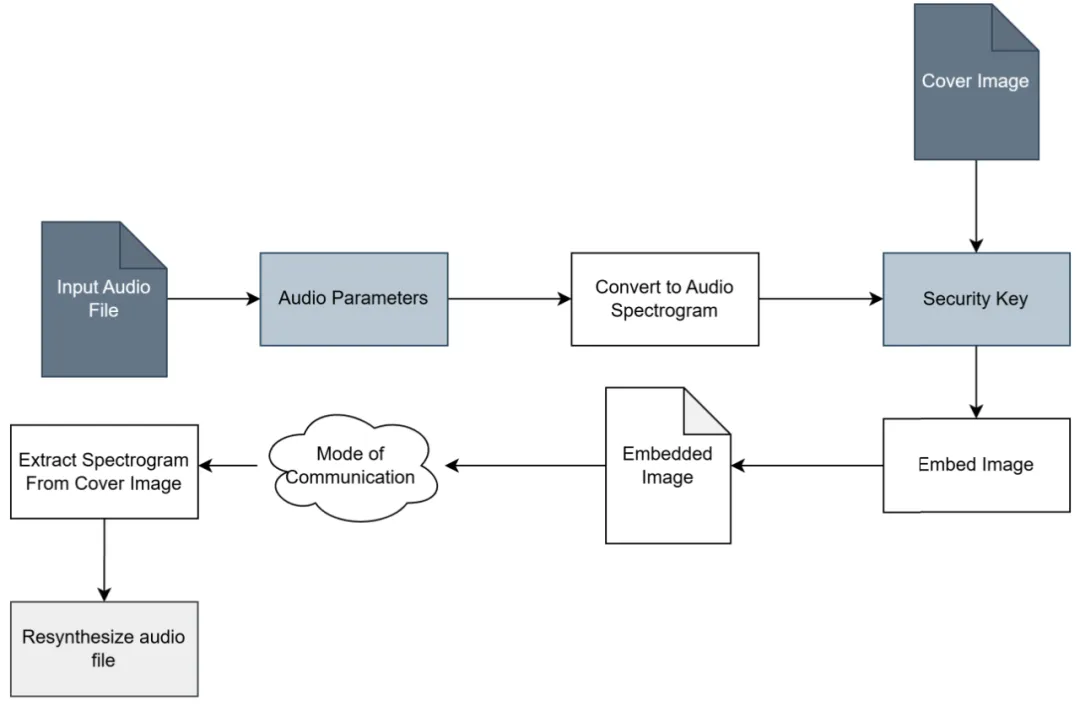
ASA 音频隐写技术:一种不依赖深度学习的音频 – 图像隐写方案
实时互动网
·

深入探讨Google Cloud上BigQuery的图像嵌入与向量搜索
KDnuggets
·

实施多模态检索增强生成系统
MachineLearningMastery.com
·
