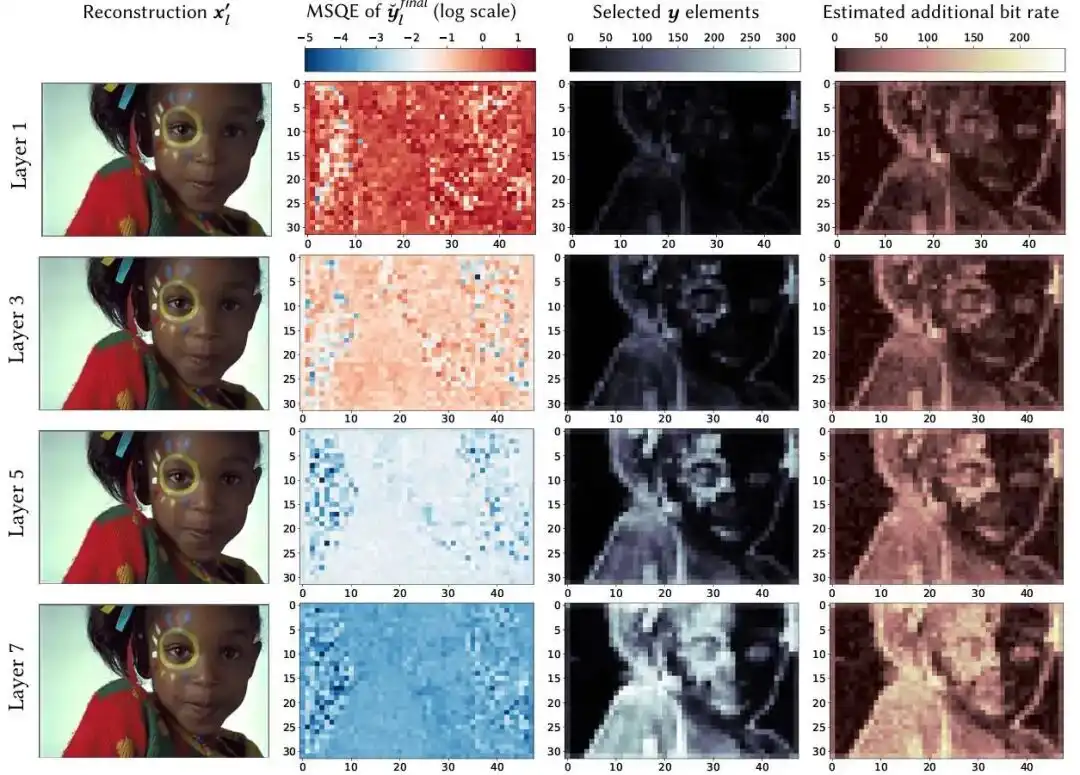
本文提出了一种名为DeepHQ的渐进式图像压缩方法,通过学习量化步长提升压缩效率,并引入选择性压缩,仅编码必要的特征,显著减少模型参数和解码时间。
DCM标准已获国家标准立项,标志着我国在基于人工智能的图像编码领域的新进展。该标准旨在以低计算成本实现高效压缩,广泛应用于工业和医疗等领域。与国际标准相比,DCM在相同精度下可节省60.73%至76.39%的数据量,提升AI效率。该技术已在卫星通信等场景中试点应用,有效解决高丢包和高时延下的实时通信问题。
我在研究Step1X-Edit扩散模型,该模型通过vlm编码文字指令和图像,提供高效的图片编辑解决方案。文章详细描述了模型的执行流程,包括图像编码、降采样、噪声构建和去噪过程,旨在分享对该模型的理解和应用。
第五届全国人工智能大赛(NAIC)将于12月13日启动,设有多个赛道,奖金总额233万元。其中“AI+图像编码”赛道报名截止至2月28日,旨在解决解码复杂度、模型泛化性和主观质量提升的挑战,要求参赛者在限定条件下进行图像高保真重建。大赛由深圳市科技创新局等主办,提供高质量数据和算力支持。
本文介绍了一种新型图像编码方案,结合压缩模型与生成模型,旨在提升编码效率与视觉识别准确性。研究探讨了视频编码对视觉识别任务的影响,并提出了优化图像压缩与视觉分析的模型。
AMD 的 David Rosca 在 Mesa 24.3 中改进了开源视频加速,新增对 AV1 静态图像编码的支持,主要用于 AVIF 图像。通过修改约 100 行代码,Radeon GPU 上的静态图像编码功能现已正常工作。
本文研究多视图图像压缩中的问题,现有方法在视差较大时效果不佳。我们提出了一种基于学习的3D高斯几何先验的多视图图像编码方法,能够更准确地估计视差,并通过深度图压缩模型减少视图之间的冗余信息。实验表明,该方法在性能上优于传统和学习基础的方法,同时保持快速的编码和解码速度。
本文介绍了一种交叉模态检索系统,利用图像和文本编码实现高效检索,避免了使用不同网络的缺点。该系统在多个数据集上评估,展示了在视频和图像检索中的优越性能,并在电子商务平台Shopee中显著提升了用户点击和订单量。
本文介绍了一种新颖的图像压缩方法,结合非线性分析变换、均匀量化器和非线性合成变换,优化了速率失真性能。高位和极低位量化方法在深度信息利用上表现出色,并在图像检索和识别中优于现有技术。此外,研究展示了基于向量量化的生成模型和创新的PTQ算法,提升了压缩比和训练效率。
本研究针对传统图像压缩方法未能满足机器智能任务的需求,提出了一种新颖的图像编码框架ICM,通过利用大规模多模态模型(LMMs)的语义理解能力,在压缩前解耦图像内容,从而实现更符合下游任务需求的编码。该方法“SDComp”显示出更灵活的重建结果和优越的视觉质量,能够有效支持多种视觉分析任务。
本研究提出了新的图像编码框架Prompt-ICM,解决了压缩策略调整和特征适应性问题,支持高效智能任务。通过深度卷积神经网络实现超分辨率重建和伪影去除,表现优异。设计的基于提示学习的恢复网络在盲目压缩图像增强挑战中获得第一名。新的视频超分辨率模型有效恢复高分辨率内容,并在超分辨压缩视频方面表现出色。
PO-ELIC提出了一种高效的图像编码模型,利用对抗性训练技术提升感知品质。研究中介绍了上下文自适应熵模型、空间-通道自适应编码算法及平行化友好的上下文模型,显著提高了图像压缩性能。实验结果表明,这些方法在PSNR和MS-SSIM指标上优于传统编解码器,具有更好的压缩效率和速度。
通过分析电磁波对降雨的影响,以及其对移动网络性能的影响,本文提出了一种将时间序列数据编码为图像并利用卷积神经网络作为图像分类问题的新方法,以解决在 4G/LTE...
本文介绍了一种新型图像编码方案,结合压缩模型和生成模型,支持机器视觉和人类视觉感知。研究重点在生成任务和3D内容操作,提出了音频视觉语音增强系统,利用扩散模型改善语音质量。同时探讨了生成对抗网络在社会过程研究中的应用,以及深度学习在超分辨率图像和视频中的进展,强调未来的挑战与机遇。
本文研究了一种可扩展的图像和视频编解码器,结合机器视觉与人类视觉,旨在提高图像压缩效率并降低比特率。通过特征融合和条件编码,提出的新方法在物体检测和人类视觉任务中表现优越,提供了人机协同压缩的新见解。
本文研究了一种可扩展的图像编解码器,旨在提高机器视觉任务的比特率效率,同时保持人类视觉感知的性能。该方案结合了压缩模型和生成模型,在物体检测和图像重建方面表现优异,显著节省比特率并优化任务准确性。实验结果表明,该模型在视频监控和图像压缩中具有良好性能,提供了人机协同压缩的新见解。
本文探讨了大型语言模型(LLMs)在医学图像分析和多模态任务中的应用,评估其在生物医学领域的性能。研究表明,LLMs在小样本数据集上表现优于传统模型,且无需微调即可理解视觉信号。通过创新的图像编码方法,LLMs在图像识别、生成和多模态对话等任务中展现出潜力。
本研究提出了一种基于深度学习的图像压缩模型,旨在提高图像编码的视觉质量和机器分析准确性。通过对抗训练和自我监督学习,该模型在物体检测和语义分割任务中显著提升了性能,并减少了比特率需求。实验结果表明,该技术有效消除了伪影,在多个视觉任务中表现优越。
该研究提出使用神经网络辅助的额外lifting步骤来增强传统小波变换中的冗余性,提高降低分辨率后重建图像的视觉质量。应用于JPEG 2000图像编码标准中,能够在广泛的比特率范围内实现高达17.4%的平均BD比特率节省,同时保持JPEG 2000的质量和分辨率可扩展特性。
本研究提出了一种基于对抗训练的图像编码技术,提高视觉质量,保持机器分析准确性,无需增加比特率或参数。实验证明,该技术消除棋盘格伪影,提高像素和特征保真度分数。
完成下面两步后,将自动完成登录并继续当前操作。