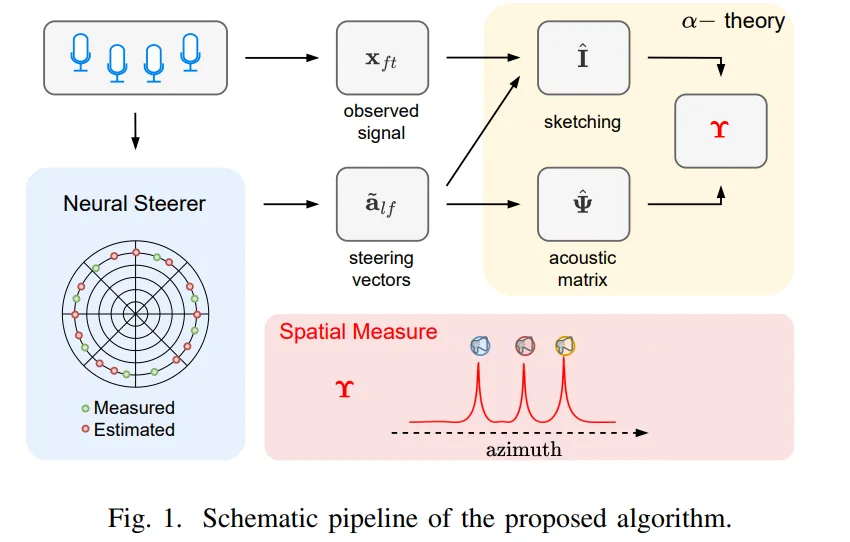
声源定位(SSL)在增强听觉和自动驾驶等领域应用广泛。日本理化学研究所提出的新型混合技术SHAMaNS,结合α稳定模型与神经网络,成功解决了稀疏测量和噪声鲁棒性问题。实验结果显示,SHAMaNS在多声源场景中表现优异,适应能力强,未来计划扩展至三维定位。
本文研究了声音场特性与声源及听者周围环境的几何和空间属性之间的关系。提出的方向意识神经场利用Ambisonic格式的环境冲激响应,显著提高了对不同房间适应性的能力,可能对声场模拟产生重要影响。
港科大与北邮团队在ICLR 2025上展示了一项创新技术,能够通过文本控制声源方向生成多通道音频,显著提升空间音频生成的控制能力,具有广泛的应用前景。
本研究利用深度学习和卷积神经网络对肺音记录进行呼吸相检测,结果表明算法与专家标注高度一致,适用于呼吸相检测。同时,研究提出了一种基于机器学习的睡眠评估模型,通过监测睡眠声音评估睡眠质量,准确率达到94.8%。此外,研究创新性地应用深度学习对打鼾声进行分类,提升了阻塞性睡眠呼吸暂停的诊断效果。
本文介绍了多种音频处理模型和数据集,包括用于混合音频源分离的Spectro-Temporal Transformer、用于波形生成的DiffWave、用于3D声学渲染的SoundSpaces 2.0,以及RealImpact和Real Acoustic Fields数据集的构建与应用。这些研究提升了音频生成和分离的质量与泛化能力,推动了音频与视觉结合的技术发展。
本文介绍了一种新颖的无监督学习算法,通过声音和视觉场景定位声源。研究提出了多种方法,包括基于双流网络的半监督学习、迭代对比学习框架和自监督预测学习,均在声音定位任务中表现优异。False Negative Aware Contrastive方法有效解决了错误负样本问题,提升了定位准确性。最新的Tri-modal joint embedding模型展示了在多源混合中分离音视源的能力,具有良好的零-shot迁移性能。
本文介绍了一种基于深度学习的多声源定位方法,利用神经网络和自监督学习技术,在不同环境中实现准确的声源定位。研究表明,该方法在多个基准测试中优于传统技术,展现出更高的可靠性和泛化能力。
本文提出了一种跨模态对齐任务,旨在提高音频和视觉模态的交互,增强声源定位和跨模态检索的性能。研究开发了音频-视觉空间整合网络和无监督算法,利用空间线索和递归注意机制,提升声源定位的准确性和可靠性。实验结果表明,该方法在多个数据集上优于现有技术。
本文介绍了一种自监督预测学习(SSPL)方法,通过正样本挖掘实现声音定位,并结合声音与视频帧的增强视图。实验结果表明,SSPL在声音定位基准测试中表现优异,显著提升了性能。此外,研究还提出了多种无监督和半监督学习算法,以提高声源定位的准确性和可靠性。
本文介绍了一种基于深度学习的多声源定位算法,利用多个麦克风阵列在封闭环境中确定声源的二维坐标。该算法通过编码-解码结构和改进措施,在合成和真实数据测试中优于现有方法。此外,提出了新的无监督学习算法和音频-视觉整合网络,提升了声源定位的准确性和可靠性。
介绍了多模态声音混合编辑器'LCE',可根据用户文本指令修改声源。系统通过聊天界面和语言模型解释,同时编辑多个声源,提高信号质量。实验证明在不同声源场景中表现稳健。
本文研究了基于注意力的空间滤波技术,包括线性和非线性方法,以提高多通道语音增强算法在实际场景中的性能。实验结果表明,这些方法在静态和动态声音环境中均表现出鲁棒性,并优于传统的空间滤波方法。
该文介绍了一个跨模态对齐任务,以促进音频和视觉模态之间的交互学习,实现了声源定位和跨模态检索的高性能和语义理解。
本文提出了使用注意力特征融合的通道重新校准方法进行DeepFake Audio检测,并改进了Resnet模型的输入特征嵌入方式。经过训练,模型在Fake or Real数据集上获得了95%的测试准确度,并在使用不同的生成模型生成样本后适应该框架后,达到了90%的平均准确度。
本文介绍了一种双输入神经网络(DI-NNs)方法,用于信号处理应用中的元数据和高维信号建模。通过训练和评估DI-NNs在不同情景下的性能,并与其他替代架构以及最小二乘(LS)方法和卷积递归神经网络(CRNN)进行比较。结果表明,在真实录音测试数据集中,DI-NNs的定位误差比LS方法低五倍,比CRNN低两倍。
完成下面两步后,将自动完成登录并继续当前操作。