
多声源定位新方法:结合α稳定模型与神经网络的SHAMaNS
内容提要
声源定位(SSL)在增强听觉和自动驾驶等领域应用广泛。日本理化学研究所提出的新型混合技术SHAMaNS,结合α稳定模型与神经网络,成功解决了稀疏测量和噪声鲁棒性问题。实验结果显示,SHAMaNS在多声源场景中表现优异,适应能力强,未来计划扩展至三维定位。
关键要点
-
声源定位(SSL)在增强听觉、机器人技术和自动驾驶等领域应用广泛。
-
现有SSL技术主要分为声学信号处理、数据驱动深度学习和混合方法三类。
-
稀疏测量和非高斯噪声鲁棒性是声源定位技术的主要难点。
-
日本理化学研究所提出的新型混合技术SHAMaNS结合了α稳定模型与神经网络。
-
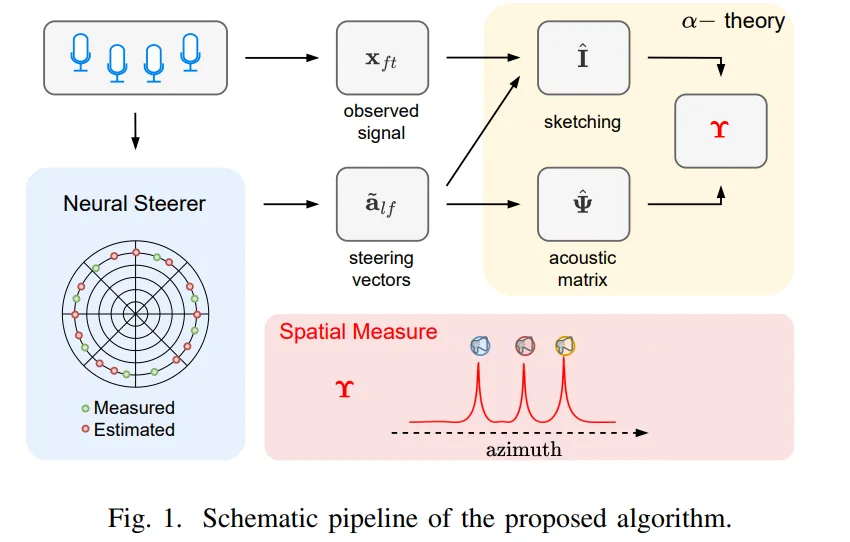
SHAMaNS通过空间测度模型和Neural Steerer模型解决了导向向量的稀疏测量问题。
-
该技术在多声源场景中表现优异,定位准确率超过基线方法。
-
SHAMaNS在仅有32个随机测量的情况下仍能保持合理性能,显示出良好的适应能力。
-
未来计划将SHAMaNS扩展至三维定位,并探索与声源分离的联合应用。
延伸解读
技术背景与挑战
声源定位技术在增强听觉和自动驾驶等领域至关重要,但稀疏测量和非高斯噪声的鲁棒性一直是技术发展的瓶颈。SHAMaNS通过结合α稳定模型与神经网络,提供了一种创新的解决方案,展示了在复杂环境下的潜力。
SHAMaNS的优势
SHAMaNS在多声源场景中表现出色,尤其是在仅有32个随机测量的情况下,仍能保持合理的定位性能。这一特性使其在实际应用中具有较强的适应能力,尤其适合数据稀缺的环境。
未来发展方向
研究团队计划将SHAMaNS扩展至三维定位,并探索与声源分离的联合应用。这一发展将进一步提升声源定位技术的应用范围,可能在机器人和自动驾驶等领域带来新的突破。
延伸问答
SHAMaNS技术的主要创新点是什么?
SHAMaNS结合了α稳定模型与神经网络,解决了稀疏测量和噪声鲁棒性问题。
SHAMaNS在多声源场景中的表现如何?
在多声源场景中,SHAMaNS的定位准确率超过了基线方法,表现优异。
SHAMaNS如何处理稀疏测量问题?
SHAMaNS通过引入Neural Steerer模型,实现对全空间导向向量的高精度插值,仅需32个随机测量点。
SHAMaNS的未来发展计划是什么?
未来计划将SHAMaNS扩展至三维定位,并探索与声源分离的联合应用。
SHAMaNS在噪声环境下的鲁棒性如何?
SHAMaNS通过α稳定模型对脉冲噪声和模型误差具有天然鲁棒性。
SHAMaNS的实验评估是如何进行的?
实验使用6通道麦克风阵列和多种声学场景,评估SHAMaNS在不同声源数量和信噪比下的表现。
