
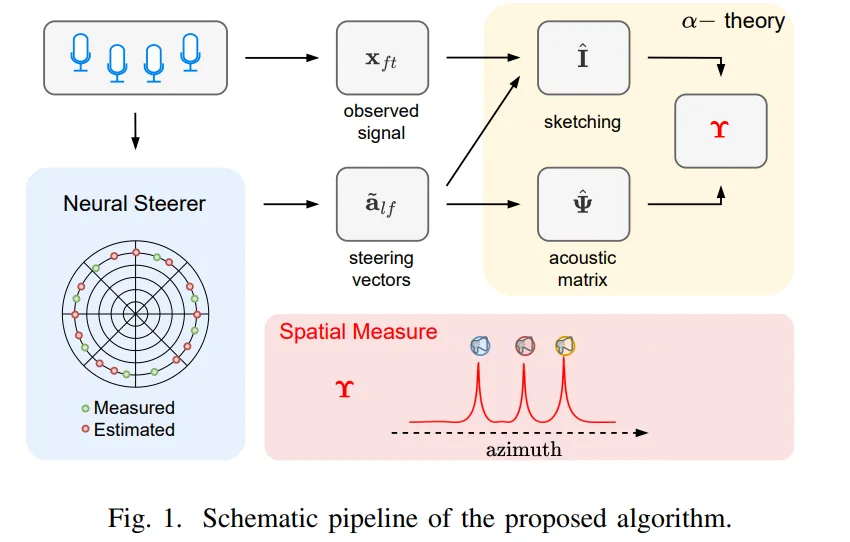
多声源定位新方法:结合α稳定模型与神经网络的SHAMaNS
实时互动网
·

移远通信推出端&云混合大模型机器人大脑解决方案
全球TMT-美通国际
·

基于3D重建房间的新视角声学合成
Apple Machine Learning Research
·
声源定位是关于跨模态对齐的全部内容
BriefGPT - AI 论文速递
·
