当前AI智能体普遍存在记忆缺陷,无法有效记住用户信息。文章分析了三种解决方案:使用文本文件、外部知识库和向量数据库。第一种方法简单但难以扩展,第二种方法灵活但复杂,第三种方法效果最佳但搭建难度大。解决智能体记忆问题是提升其智能化的关键。
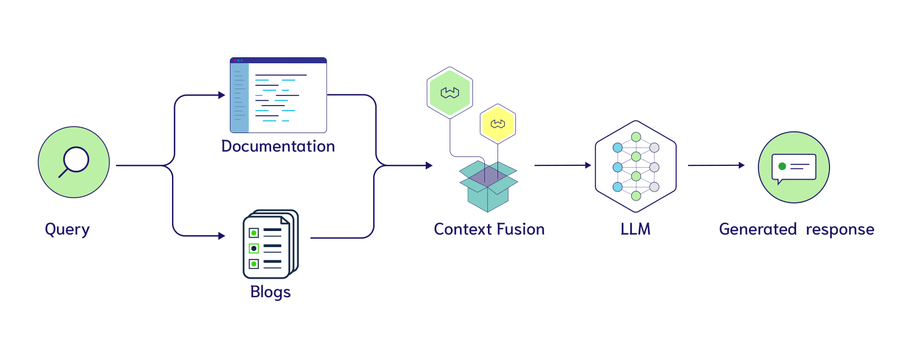
大型语言模型(LLM)的表现依赖于输入上下文,缺乏实时企业数据可能导致错误回答。检索增强生成(RAG)通过在回答前检索相关信息,结合语言模型与外部知识库,确保回答基于最新的上下文,从而提升企业的信任度和响应质量。
文章讨论了语言模型与智能体的区别。语言模型如GPT-4能够理解语言,但知识有限;智能体则具备自主决策能力,能通过问题分类、工具使用和优化答案来提高回答质量。训练分类模型和利用外部知识库是解决模型知识局限性的关键步骤。
本文探讨了检索增强生成(RAG)技术的改进方法,包括动态相关检索框架(DR-RAG)和查询重写方法(MaFeRw)。通过引入外部知识库和多方面反馈,提升了文档检索的准确性和生成响应的质量。此外,提出了全面链评估框架(CoFE-RAG)以解决数据多样性不足的问题,实验结果表明这些方法在问答系统中表现优异。
大型语言模型(LLMs)在应用中面临幻觉和知识更新慢等挑战。检索增强生成(RAG)技术通过外部知识库提升LLMs的回答质量。研究总结了RAG的三种范式及其组成部分,探讨了评估方法和未来研究方向,强调有效整合外部数据的重要性,以提高LLMs的推理能力和实用性。
RAG系统通过引用外部知识库来优化大型语言模型(LLM)的输出,从而提高信息检索的准确性。随着自然语言处理技术的发展,RAG市场预计将迅速增长。优化嵌入技术对提升RAG系统性能至关重要,需关注领域适应性和对比学习等方法。
RAG(检索增强生成)结合大型语言模型与外部知识库,提高回答的准确性和可解释性。随着技术进步,RAG需要演变为具备感知、决策和行动能力的Agent,以满足复杂应用需求,实现更高级的智能交互和服务。
本研究分析了检索增强生成(RAG)对大型语言模型(LLMs)的影响,提出了新的框架和评估方法,强调外部知识库整合对提高检索精度和答案准确性的重要性。研究发现特定文档类型能显著提升生成效果,并指出未来研究方向。
大型语言模型(LLMs)面临幻觉和知识更新缓慢等挑战。检索增强生成(RAG)通过外部知识库提升LLMs的性能。本文总结了RAG的三种范式及其组成部分,讨论了评估方法和未来研究方向,强调了RAG在医疗领域的应用潜力和技术基础。
大型语言模型(LLMs)面临幻觉和知识更新缓慢等挑战。检索增强生成(RAG)通过外部知识库改善LLMs的输出。论文总结了RAG的三种范式及其组成部分,讨论了评估方法和未来研究方向,强调了RAG在提高准确性和可靠性方面的潜力。
本文介绍了一种名为InFO-RAG的信息优化训练方法,旨在提升大语言模型在检索增强生成中的表现。该方法通过优化检索文本,提高生成文本的准确性和完整性,相较于LLaMA2性能提升9.39%。研究探讨了RAG的三种发展范式及其评估方法,并提出了改进文本检索的技术,强调外部知识库在提高答案准确性中的重要性。
本文提出了一种基于解释的微调方法,以增强大型语言模型在分类任务中的稳健性。通过生成支持答案的自由文本解释,模型在伪线索下表现更佳。此外,研究探讨了利用外部知识库和无标注数据进行微调,以提升事实核查的性能。实验结果显示,GPT-4在零提示场景中表现突出,而开放源模型在少提示和微调情况下也表现良好。
该研究探讨了大型语言模型(LLM)在事实准确性评估中的应用,提出了多阶段注释方案和工具,以识别输出中的事实错误。实验表明现有工具在识别错误声明方面效果不佳,LLM在事实检查中存在局限性。研究还提出了自监督框架Self-Checker,以提高事实检查效率,并强调外部知识库在提升LLM准确性中的重要性。
本文探讨了通过自我评估和知识调整提升大型语言模型(LLMs)事实准确性的方法。研究表明,结合外部知识库和强化学习技术,可以显著改善模型生成内容的正确性,尤其是在多模态模型中解决模态不匹配问题。此外,提出了一种新颖的事实推理方法和自动虚构注释工具,以增强模型的真实性和诚实性,提升教育领域的应用效果。
大型语言模型(LLMs)面临幻觉和知识更新慢等挑战。检索增强生成(RAG)通过外部知识库提升模型性能。论文总结了三种RAG范式及其关键技术,讨论了评估方法和未来研究方向。研究表明,RAG在医学和教育等领域的应用显著提高了模型的准确性和鲁棒性。
GPT-4-turbo是下一代RAG,可以处理128K输入令牌。RAG是一个人工智能框架,用于从外部知识库检索事实,提高大语言模型的质量。GPT-4-turbo的长上下文窗口可以克服搜索的局限性。多索引RAG可以从多个来源提取上下文,提高上下文涌现潜力。
完成下面两步后,将自动完成登录并继续当前操作。