国产开源语音模型VoxCPM 2成功复刻郭德纲的《莽撞人》,展现高保真、多方言和多语种能力,音质达到CD级别,适用于游戏和影视等领域,吸引了众多用户体验。
Mistral AI于2026年2月开源了Voxtral Mini 4B Realtime 2602模型,支持13种语言的实时语音转录,延迟低于500毫秒,适合轻量化应用,并可在边缘计算单元上部署,提升语音识别的精度与效率。
PaddleOCR于2025年推出PaddleOCR-VL-1.5,具备94.5%精度,支持异形框定位,提升文本行和印章识别能力。该模型在复杂场景中表现优异,已开源,用户可通过官网和API使用。新版本优化了推理速度,支持多语种和跨页表格合并,旨在提升文档解析的准确性和效率。
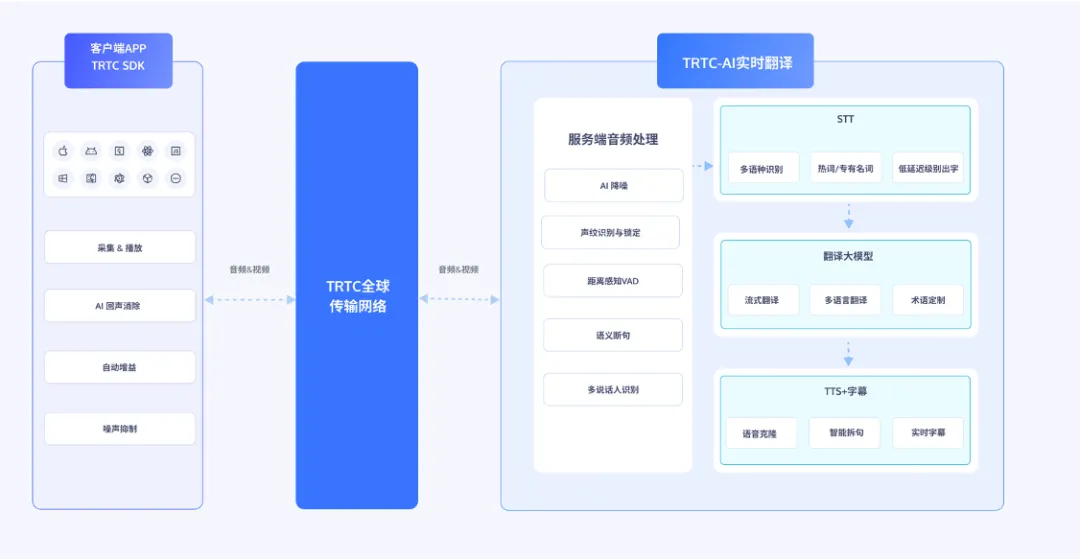
腾讯云推出的AI实时翻译方案,具备毫秒级延迟和多语种支持,提升了用户在直播、电商客服和会议等场景中的交流体验,打破语言障碍。
B站推出AI原声翻译功能,提升海外用户体验,支持多语种视频,完美还原UP主声线,解决翻译中的情感与风格保留问题,未来将扩展更多语言。
PaddleOCR 3.1 更新了多语种文本识别模型,支持37种语言,识别精度提升30%。新增文档翻译工具PP-DocTranslation,支持Markdown、PDF和图片格式翻译,并支持MCP服务器,便于将OCR能力集成到AI应用中。
本研究解决了视觉语言模型(VLM)在处理多语种输入时生成英语回复的限制问题,提出了一种连续的多语种融合策略,在视觉指令调优过程中注入文本多语种数据,从而保留语言模型的多语种能力。研究结果表明,该方法在不影响视觉性能的前提下显著提升了多语言的语言保真度,提供了一个有效的解决方案以推动全球VLM的应用。
本研究提出了一种新方法——多因素平衡ICL(BMF-ICL),旨在解决多语种大型语言模型在上下文学习中因示例选择导致的有效性差异。实验结果表明,BMF-ICL在多个模型上优于现有方法,强调了整合多因素的重要性。
本文介绍了博利项目,旨在解决印度语言中口吃语音数据稀缺的问题,构建了多语种口吃语音数据集,包含匿名元数据、问卷回应及朗读、自发言语记录,并详细注释五种口吃类型,为相关研究和技术发展提供了重要资源。
四川中行与科大讯飞合作推出多语种AI透明屏,提升境外游客支付便利性,支持实时翻译,优化金融服务体验。
本研究探讨了多语种自然语言处理中的英语角色,指出其在任务性能与语言理解之间存在目标不一致,建议应重视增强语言理解,而非单纯依赖英语提升任务性能。
本文提出了一种基于并行语料库和合成数据增强的策略,旨在提升印度36种语言的机器翻译质量,促进多语种交流。
本研究探讨了多语种检索增强语言模型在处理多样语言时的挑战,提出了《Futurepedia》基准测试,评估六个多语种RALMs,揭示语言资源不均等问题并提出改进建议。
本研究探讨了多语种大型语言模型(MLLMs)的开发与应用,提出了优化多语种能力的策略,并分析了技术和文化视角。研究强调支持语言多样性的重要性,指出88.38%的世界语言为低资源,影响超过十亿用户。
本研究探讨了大型语言模型在非英语语言中的信心估计不足问题。通过多语种信心估计(MlingConf)方法,发现英语在语言无关任务中表现优越,而使用相关语言提示可显著提升语言特定任务的信心估计,从而提高模型的可靠性和准确性。
研究分析了分词对多语种语言模型形态知识的影响,比较了mT5和ByT5在不同语言上的形态学理解。结果表明,中晚层编码的形态信息显著影响模型表现,尤其在处理不规则语言时,增加预训练数据能提升效果。
本研究提出了DEPT框架,旨在解决多语种和领域数据异质性对语言模型预训练的负面影响。通过解耦嵌入层与变换器主体,DEPT显著提高了模型的泛化能力,并减少了嵌入参数数量,实现了无词汇依赖的联邦多语言预训练。
本文探讨了低资源语言的多语言自动语音识别(ASR)技术,提出通过单个transformer模型和数据增强方法来提高识别精度。研究表明,多语言训练显著提升了低资源语言的识别性能,尤其在51种语言的基准测试中表现突出。通过跨语言学习和适应性激活网络等技术,展示了在低资源环境下的有效性和潜力。
该论文探讨了多语种自动语音识别和情感识别的最新进展,提出了一种基于半监督学习的情感识别方法,并比较了跨语言与单语言模型的表现。研究强调了数据增强和特征选择的重要性,结果表明跨语言训练能有效提升资源稀缺语言的情感识别能力,为未来研究提供了理论基础和评估标准。
本文探讨了序列到序列神经翻译模型在多语种新闻监测中的故事分割和聚类问题。通过滑动窗口机制和字符级操作,提出了一种有效的多任务学习方法。研究表明,低维向量在故事聚类和分割中具有潜力,并介绍了多语言上下文嵌入的在线系统,取得了最新成果。
完成下面两步后,将自动完成登录并继续当前操作。