以色列初创公司Deepdub推出了Lightning 2.5实时语音模型,性能显著提升,适用于联络中心和AI代理。该模型吞吐量提高2.8倍,延迟低至200毫秒,优化了NVIDIA GPU环境,支持多语言对话和媒体本地化,保持语音自然和情感细腻。
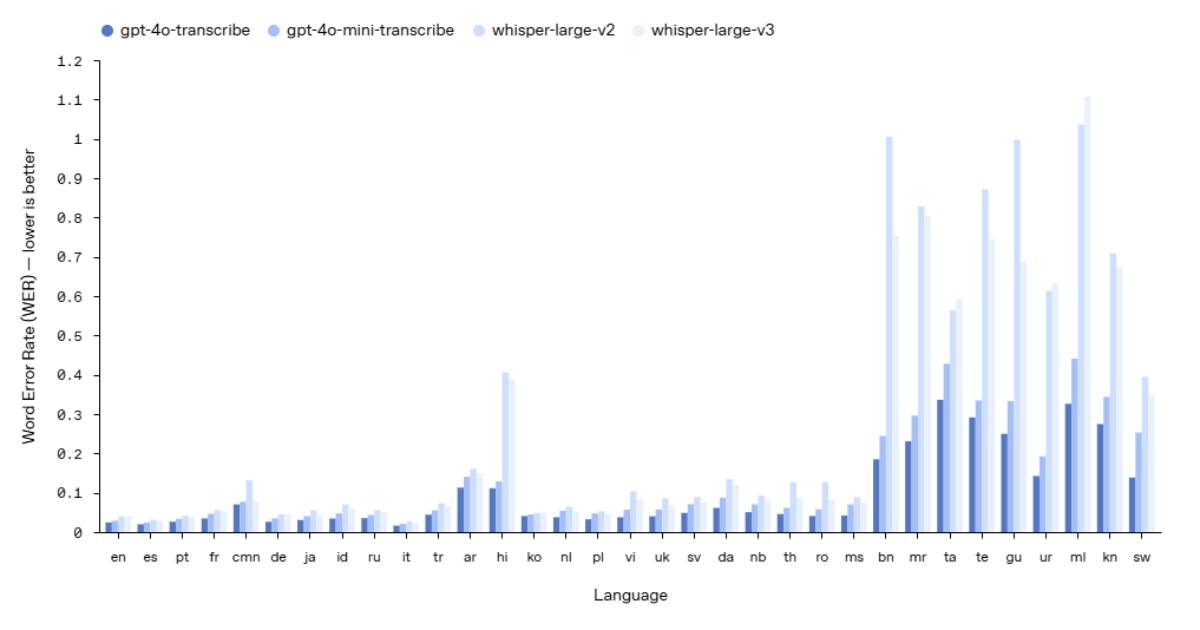
OpenAI推出了新的语音转文本和文本转语音模型,提升了转录准确性,特别在处理口音、背景噪音和语速变化方面表现优异,适合客户支持和多语言对话。开发者可通过API集成并定制AI语音风格。尽管与行业领先者仍有差距,但其易用性和市场份额吸引了开发者。
本研究提出了一种新方法,通过大型语言模型生成多语言对话数据,有效解决开放领域对话模型的数据稀缺问题。该方法能够捕捉语言细微差别,某些任务的表现超过人类众包工作者,展现出良好的应用前景。
本研究提出了XMP数据集,以解决多语言对话系统中高质量数据集不足的问题。该数据集包含多方播客对话的平行文本样本,旨在推动大型语言模型在复杂对话场景中的表现机制研究。
本文讨论了多语言对话评估的进展,重点介绍了基于英文数据集的 xDial-Eval。研究引入了 SocialDial 和 CGoDial 数据集,提出了新的评估方法 PairEval,并评估了对话系统的个性化和质量。通过对不同模型的比较,提供了对对话评估指标的深入见解,为未来研究提供指导。
完成下面两步后,将自动完成登录并继续当前操作。