
OpenAI推出新的语音模型用于转录和语音生成
内容提要
OpenAI推出了新的语音转文本和文本转语音模型,提升了转录准确性,特别在处理口音、背景噪音和语速变化方面表现优异,适合客户支持和多语言对话。开发者可通过API集成并定制AI语音风格。尽管与行业领先者仍有差距,但其易用性和市场份额吸引了开发者。
关键要点
-
OpenAI推出新的语音转文本和文本转语音模型,提升转录准确性。
-
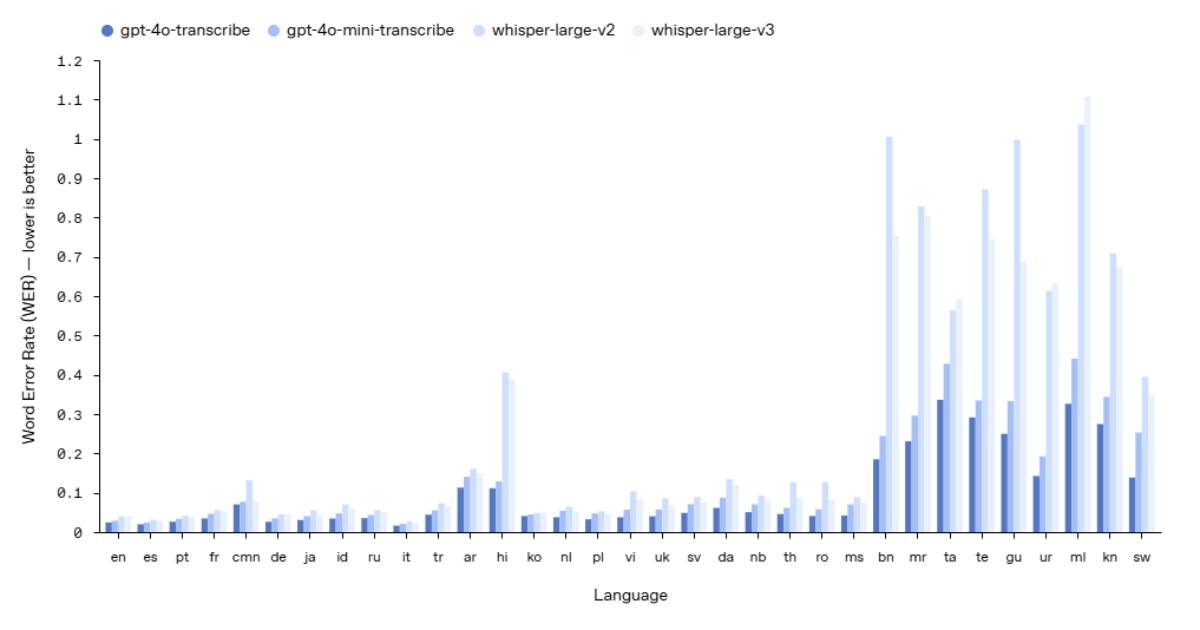
新模型gpt-4o-transcribe和gpt-4o-mini-transcribe在处理口音、背景噪音和语速变化方面表现优异。
-
这些模型适合客户支持、会议转录和多语言对话等实际场景。
-
训练改进和多样化数据集的使用减少了转录错误,提高了口语识别能力。
-
gpt-4o-mini-tts模型允许开发者定制AI语音风格,适应不同上下文。
-
尽管声音仍为合成,但OpenAI注重保持一致性和质量。
-
用户对新模型反应积极,称其为寻找合适风格的良好平台。
-
开发者欣赏模型的无缝集成和易用性,认为其适合多种应用。
-
新模型现已可用,开发者可通过Agents SDK集成语音功能。
-
OpenAI计划进一步提升音频模型的智能和准确性,并探索定制语音的可能性。
延伸解读
模型的实际应用场景
OpenAI的新语音模型在客户支持、会议转录和多语言对话等场景中表现出色。这些应用场景的多样性使得开发者能够根据具体需求选择合适的模型,从而提高工作效率和用户体验。
与行业竞争者的比较
尽管OpenAI的语音模型在准确性和功能上有所提升,但与行业领先者如ElevenLabs相比,仍存在一定差距。这意味着开发者在选择时需考虑具体需求,评估不同模型的优缺点。
开发者的反馈与期望
开发者对新模型的反应积极,尤其是其易用性和无缝集成的特点。然而,他们也期待OpenAI在未来进一步提升模型的智能和准确性,以满足更复杂的应用需求。
延伸问答
OpenAI的新语音模型有哪些主要功能?
OpenAI的新语音模型包括语音转文本和文本转语音,提升了转录准确性,特别在处理口音、背景噪音和语速变化方面表现优异。
这些模型适合哪些实际应用场景?
这些模型适合客户支持、会议转录和多语言对话等实际场景。
开发者如何使用OpenAI的新语音模型?
开发者可以通过Agents SDK将新语音模型集成到他们的应用中,简化添加语音功能的过程。
新模型在转录准确性方面有哪些改进?
新模型通过训练改进和多样化数据集的使用,减少了转录错误,提高了口语识别能力。
用户对OpenAI新语音模型的反馈如何?
用户反应积极,称其为寻找合适风格的良好平台,并对声音质量表示满意。
OpenAI对未来语音模型的发展有什么计划?
OpenAI计划进一步提升音频模型的智能和准确性,并探索定制语音的可能性。
