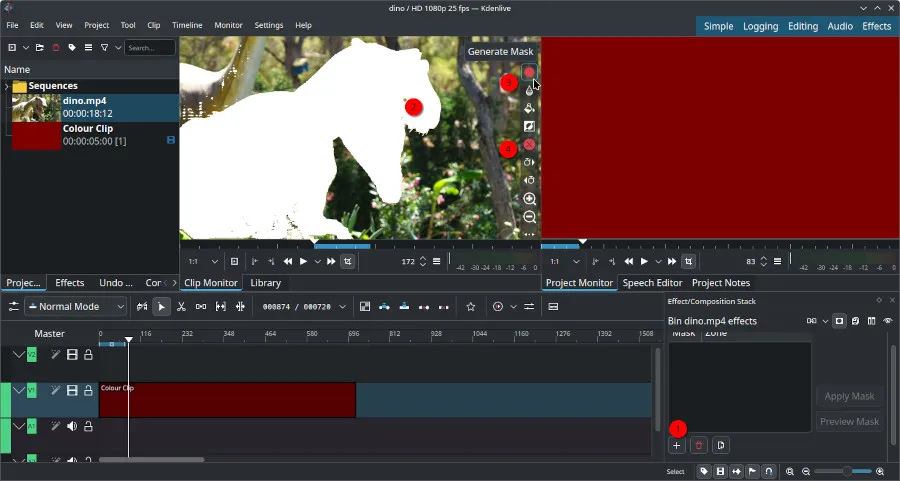
Kdenlive 25.04 发布,新增基于 SAM2 模型的对象分割插件,可移除视频背景。重构音频波形代码,优化时间线体验,支持 OpentimelineIO 导入导出,并进行了工作流程改进和错误修复。
本研究提出了一种基于长时间点轨迹的对象分割方法,克服了传统方法对瞬时运动的依赖。通过新的损失函数,将轨迹分组为低秩矩阵,有效建模复杂运动模式,提升了运动分割任务的表现,展示了长期运动的应用潜力。
本研究提出了持续SAM适应基准(CoSAM),针对动态数据流中的任意对象分割模型(SAM)适应问题。引入混合领域适配器(MoDA)算法,提升特征提取能力。实验结果表明,MoDA在持续分割任务中表现优越,具备良好的知识保留和适应性。
本文提出了一种新方法SA-GS,实现3D高斯中的对象分割,无需训练过程。通过多视角掩码生成和标签分配,SA-GS在3D分割中表现出高质量,适用于场景编辑和碰撞检测。研究还探讨了3D高斯散射的理论基础及其在视觉任务中的应用,强调高斯参数在分类和分割中的优势。
Meta发布了SAM 2,这是一个能够实时对图像和视频进行对象分割的统一模型。SAM 2在准确性和性能方面超过了以前的模型,可以在任何视频或图像中分割任何对象,无需定制。该模型具有各种潜在应用,例如创建新的视频效果和辅助视觉数据注释。Meta还分享了SA-V数据集,并发布了一个Web演示供用户尝试该模型。
Meta推出了下一代图像和视频分割模型SAM 2,支持实时对象分割,性能优于前代。该模型能够处理未见对象,适用于视频效果和数据标注等多种应用。开源代码和SA-V数据集将共享,包含51,000个视频和600,000个掩码,推理速度接近实时,推动计算机视觉的发展。
本文探讨了多种基于卷积神经网络(CNN)的3D视频处理方法,如4D卷积、伪3D残差网络和动态扩张卷积。这些方法在视频分类、特征学习和对象分割等任务中表现优于传统的2D和3D CNN,具有更高的准确性和计算效率。
本文提出了一种基于对象分割的帧间预测方法,显著提高了运动向量编码的准确性和效率。实验结果表明,该方法在多种配置下实现了显著的BD速率降低,并且在视频预测和压缩框架中表现优于现有技术,尤其在模型尺寸和编码效率方面。
本文介绍了 PartImageNet 和 PartNet 数据集,支持对象分割和少样本学习。研究提出了基于部件的模型和弱监督部件检测网络,展示了在不同数据集上的优越性能。同时探讨了多任务学习和基于特征组的图像分类方法,强调可解释性和鲁棒性。
本研究提出多种基于用户交互的对象分割方法,包括迭代训练策略、边缘引导流和文本+点击分割,旨在提高分割的准确性和用户效率。实验结果表明,这些方法在速度和准确性上优于现有技术,显著降低了用户交互成本。
本文介绍了多种基于深度学习的交互式图像和视频对象分割方法,如AGILE3D、ClickSeg和LSeg。这些方法通过减少用户点击次数和提高分割精度,显著提升了3D点云的分割效果,并在多个数据集上表现优异。研究还探讨了用户交互模式对分割结果的影响,为进一步改进提供了重要见解。
该论文综述了视频分割中使用的深度学习算法,包括对象分割和语义分割,并提供了这两种方法和数据集的详细概述,以及在几个数据集上的性能评估和未来研究机会。
OGC算法可在三维点云中实现多个3D物体的分割,无需人工标注,通过挖掘动态运动模式作为监督信号来实现。该算法考虑了多物体刚体性一致性和对象形状不变性,在室内和具有挑战性的室外场景中广泛评估,证明了其在对象实例分割和一般对象分割方面的杰出性能。
本文介绍了一个名为Segment Anything Model(SAM)的基础模型,用于视觉任务的开发。SAM可以根据廉价的输入提示在图像中进行对象分割。作者通过大量的视觉基准任务研究了SAM的零样本图像分割准确性,并发现SAM通常能够实现与目标任务上训练的视觉模型类似甚至超过其识别精度。他们还检查了SAM在多样化、广泛研究的基准任务集上的表现。然而,作者还研究了SAM在航空图像问题中的表现,发现由于航空图像和目标对象的独特特征,SAM在某些情况下会失败。
完成下面两步后,将自动完成登录并继续当前操作。

![介绍 SAM 2:下一代 Meta 视频和图像分割模型 [译]](https://scontent-ord5-1.xx.fbcdn.net/v/t39.2365-6/452258162_1278169679835253_6611651848984223695_n.png?_nc_cat=101&ccb=1-7&_nc_sid=e280be&_nc_ohc=Gwx36k7z7sUQ7kNvgHKfDLX&_nc_ht=scontent-ord5-1.xx&oh=00_AYAO2clEdTyi8UF1zXRROBNyK1VKYJj0a2hBm0HlptK_yA&oe=66C295BA)
