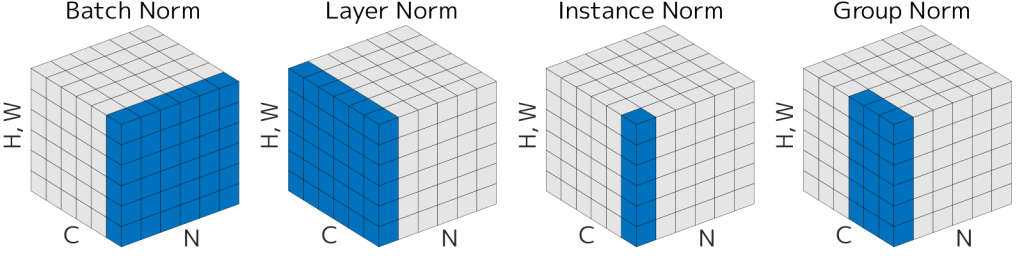
批量归一化和层归一化通过规范化激活来提高训练稳定性,减少对初始化的敏感性。批量归一化对每个训练小批量进行规范化,确保后续层输入的稳定分布;层归一化则对单个样本的特征进行规范化,适用于小批量或可变批量的情况。两者均包含可学习参数,以保持模型的表示能力。
本研究探讨了变压器模型在短序列训练后对长序列泛化不良的问题。通过分析消失方差,证明了长序列导致多头注意力模块输出方差降低。实验结果表明,在注意力输出后应用层归一化能显著改善长度泛化效果,减少分布偏移。
本研究提出了一种新型混合归一化策略HybridNorm,旨在解决深层变换器网络训练中的层归一化问题。实验结果表明,HybridNorm在密集和稀疏架构中均优于传统方法,显著提升了大语言模型的训练稳定性和性能。
本研究提出“深度诅咒”概念,针对现代大语言模型的层效能低下问题,分析发现问题源于预层归一化,提出层归一化缩放作为解决方案,显著提升模型训练效果。
本研究提出了一种新层归一化策略Peri-LN,旨在解决变压器架构中的不足。Peri-LN在大规模训练中表现优异,能够有效平衡方差、改善梯度流动并提高收敛稳定性,具有潜在应用价值。
本文探讨了神经网络中的损失可塑性问题及神经坍塌现象。研究表明,层归一化和权重衰减技术能够有效维持网络的可塑性,提升学习算法的稳健性。同时,神经坍塌现象会影响模型的泛化能力和优化能力,提出的正则化方法可以缓解可塑性丧失。
本文从几何视角揭示了Transformer操作的内部机制,说明层归一化将潜在特征限制在超球面上,塑造单词的语义表示。通过探究GPT-2模型,发现了早期层中的清晰查询-键注意力模式,并构建了关于注意力头部的特定主题性的先前观察。利用这些洞察,将Transformer描述为沿着超球面的词粒子的轨迹的建模过程。
本文从几何视角揭示了Transformer操作的内部机制,说明层归一化将潜在特征限制在一个超球面上,从而使得注意力能够塑造单词在这个表面上的语义表示。通过对GPT-2模型进行探究,发现了早期层中的清晰查询-键注意力模式,并在更深层次上进一步构建了关于注意力头部的特定主题性的先前观察。利用这些几何洞察,给出了Transformer的直观理解,将其描述为沿着超球面的词粒子的轨迹的建模过程。
完成下面两步后,将自动完成登录并继续当前操作。