

独占自注意力
Apple Machine Learning Research
·
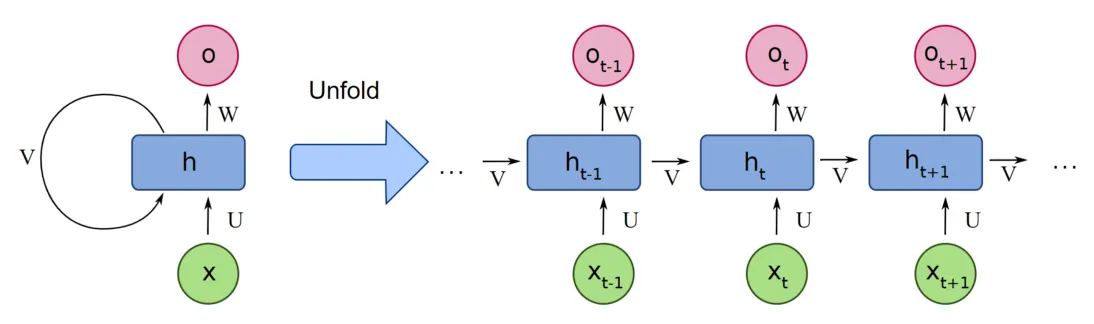
深入理解大模型 1:Transformer,大模型的基石
木鸟杂记
·

RWKV-7 '鹅'与表现丰富的动态状态演化
BriefGPT - AI 论文速递
·

突破性人工智能模型统一了基于状态空间序列的方法进行3D内容生成
DEV Community
·
基于集成学习的行为序列建模
BriefGPT - AI 论文速递
·

