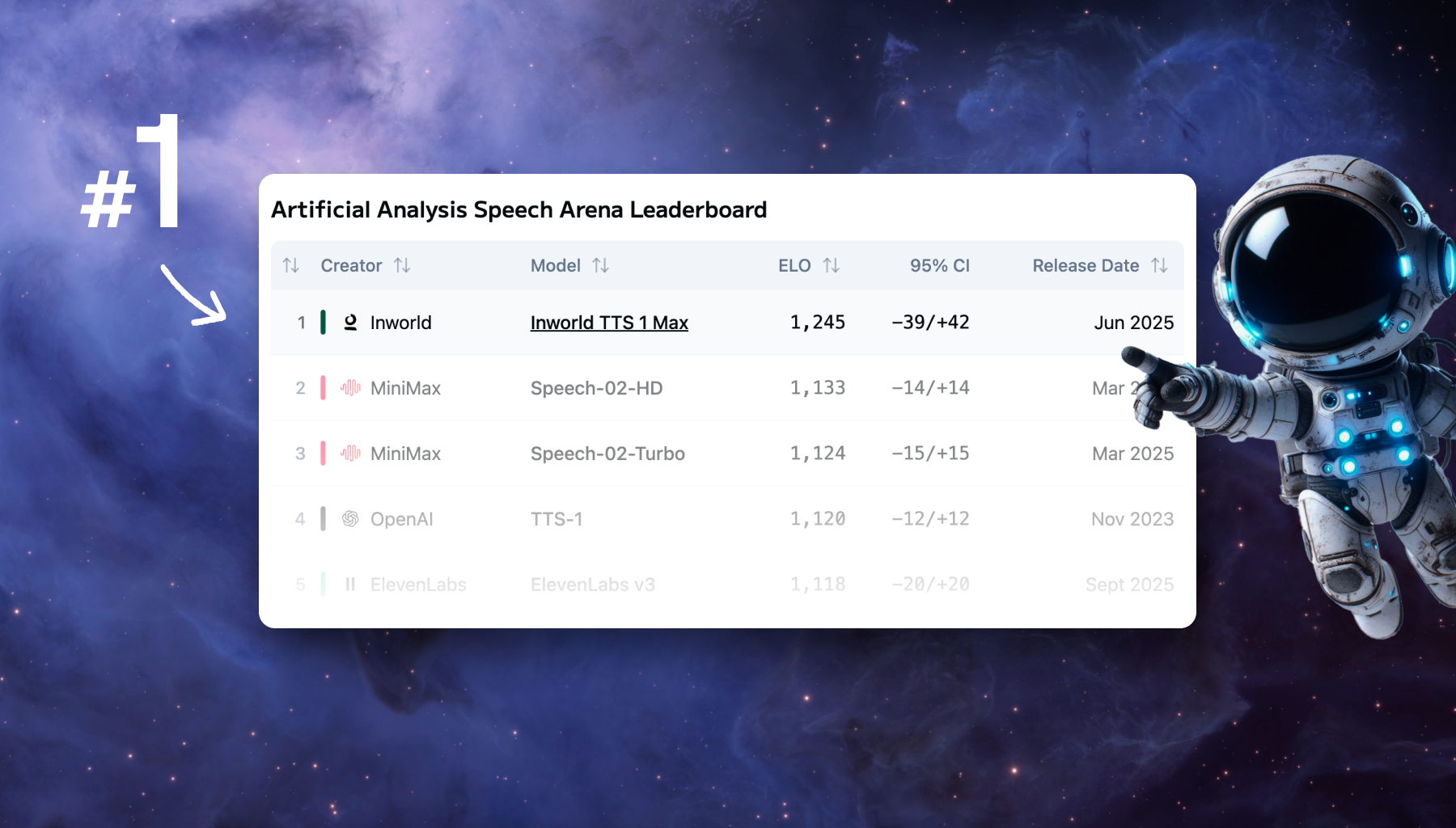
Inworld与Modular合作成功,'Inworld TTS 1 MAX'模型在语音排行榜中位列第一。该平台测试了超过100种LLM,评估其智能、速度和成本。两款模型支持12种语言,具备语音克隆和情感标签功能,提升了文本转语音的性能与效率。
本文提出了一种无训练的上下文学习方法EmoGist,用于视觉情感分类,解决情感标签的上下文依赖性问题。通过分析类别示例图像的聚类,预生成情感标签解释,从而提高分类准确性。实验结果显示,EmoGist在多个数据集上的F1分数显著提升。
本研究针对30多种低资源语言的情感检测,填补了该领域的空白。通过多条赛道的情感标签预测,提供基线结果和最佳系统表现,为多语言情感分析提供重要参考,推动跨语言情感检测的发展。
本研究提出了一种统一的多任务学习框架,针对音乐情感识别中的情感标签异构问题,结合类别和维度标签进行训练。该框架通过有效的输入表示和知识蒸馏技术显著提升了模型的泛化能力,尤其在MTG-Jamendo数据集上表现优于现有模型,推动了音乐情感识别的发展。
该论文提出了一种基于变换器的连续情感标签生成多乐器符号音乐的新方法,提高情感表达。同时提供了带有情感标签的大规模符号音乐数据集,并通过音符预测精度和情感平面的回归任务进行了评估,结果表明该方法超越了当前技术水平。
该研究提出了一种基于多任务和分层多任务学习框架的方法,用于模拟连续和离散情感标签之间的关系,并提高情感识别任务的鲁棒性和性能。实验结果显示该模型在IEMOCAP和MSPPodcast数据集上有显著的性能改进。
完成下面两步后,将自动完成登录并继续当前操作。