本文探讨了大语言模型在持续预训练中的学习动态,分析了通用性能与特定领域性能的演变,并提出了CPT缩放法则,为训练超参数优化提供新见解。
扩散语言模型(DLMs)旨在克服自回归模型的局限性。本文提出通过适应自回归模型构建文本扩散模型,展示了自回归与扩散建模目标之间的联系,并介绍了一种持续预训练方法。实验结果表明,转换后的模型在语言建模和推理基准上表现优异,超越了早期的DLMs,并与自回归模型竞争。
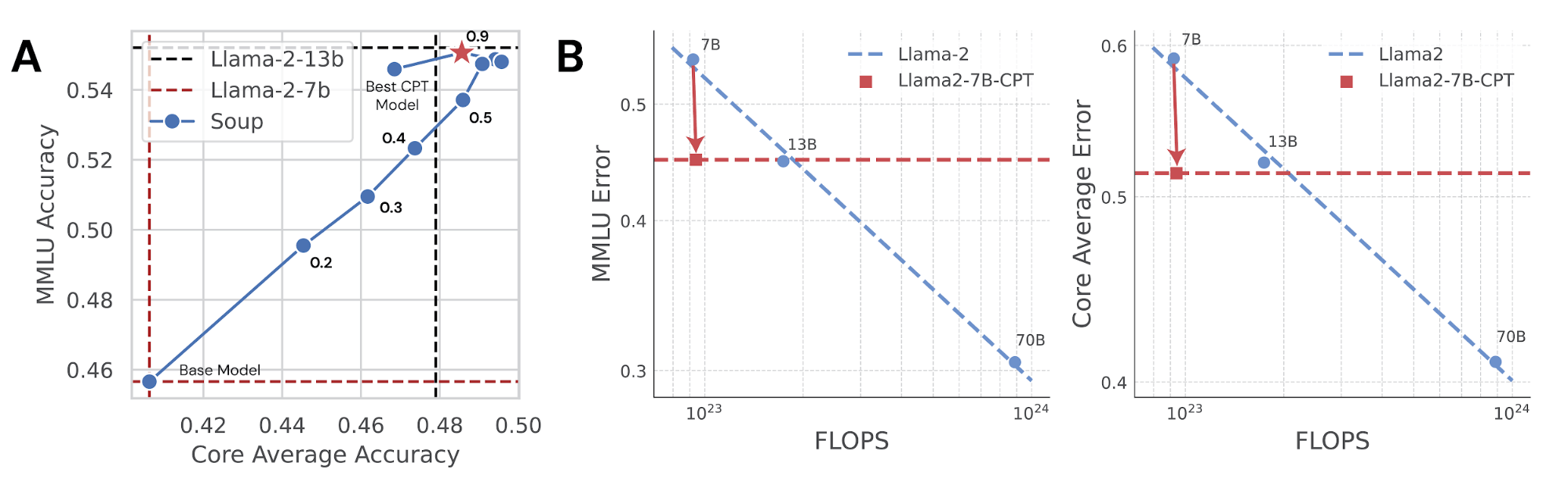
本文探讨了如何通过持续预训练(CPT)定制大型语言模型(LLM),通过在特定领域的大量文本上进一步训练预训练模型来增强领域知识。文章强调了学习率、训练时长和数据混合等超参数的重要性,并介绍了选择有效数据集以提高模型性能的方法。合理的超参数调整和数据混合能够显著提升小型LLM的表现,使其接近大型模型的水平。
这篇研究论文提出了一种简单有效的方法,用于在新数据可用时持续预训练大型语言模型。通过结合学习率逐渐增加和逐渐减小以及周期性重播之前的数据等简单技术,研究人员能够在使用更少计算资源的情况下,与完全重新训练模型的性能相匹配。这些发现对于大型语言模型的实际部署具有重要意义,使其能够以可扩展和高效的方式保持最新状态。进一步研究语言模型的持续学习技术可能会导致更强大和适应性更强的人工智能系统。
本文介绍了一系列支持高达32,768个令牌的长上下文语言模型(LLMs),通过持续预训练,这些模型在长文本任务上相较于Llama 2取得显著提升。研究表明,适当的数据混合和持续预训练策略能有效扩展上下文长度至128K,并在长上下文理解方面表现优异。实验结果显示,商业模型在短依赖任务上优于开源模型,但在长依赖任务上仍面临挑战。
本研究探讨了电子商务领域中持续预训练对大型语言模型的影响,并证明了其有效性。同时,提出了一种混合策略来更好地利用电子商务数据。
本文介绍了一种名为稳定蒸馏的方法,用于持续预训练和提升目标领域自动语音识别(ASR)性能。该方法通过自蒸馏作为正则化方式,减轻了持续预训练中的过拟合问题。实验结果表明,稳定蒸馏在不同实验设置中胜过了所有基线方法,WER 提高了0.8-7个百分点。
Amazon Bedrock现在支持在私有和安全的环境中自定义基础模型,以构建特定于您的域、组织和用例的应用程序。微调和持续预训练可提高模型的准确性和适应性。使用Amazon Bedrock控制台或API可以创建自定义模型作业。
该文介绍了支持高达32,768个令牌的长上下文LLMs,通过持续预训练构建模型系列,在语言模型、合成上下文探索任务以及广泛的研究基准上取得了显著提升。作者对Llama的位置编码和预训练过程中的设计选择进行了深入分析,验证了长上下文持续预训练相对于从头开始的长序列预训练更高效且同样有效。
完成下面两步后,将自动完成登录并继续当前操作。