
通过持续预训练对数据集进行特征化并构建更好的模型
内容提要
本文探讨了如何通过持续预训练(CPT)定制大型语言模型(LLM),通过在特定领域的大量文本上进一步训练预训练模型来增强领域知识。文章强调了学习率、训练时长和数据混合等超参数的重要性,并介绍了选择有效数据集以提高模型性能的方法。合理的超参数调整和数据混合能够显著提升小型LLM的表现,使其接近大型模型的水平。
关键要点
-
大型语言模型(LLM)在特定领域的表现可能不佳,需要通过持续预训练(CPT)进行定制。
-
CPT是通过在特定领域的大量文本上进一步训练预训练模型,以增强模型的领域知识。
-
有效的CPT需要关注三个关键超参数:学习率、训练时长和数据混合。
-
选择有效的数据集对于提高模型性能至关重要,某些数据集可能会降低模型的准确性。
-
通过合理的超参数调整和数据混合,可以显著提升小型LLM的表现,使其接近大型模型的水平。
-
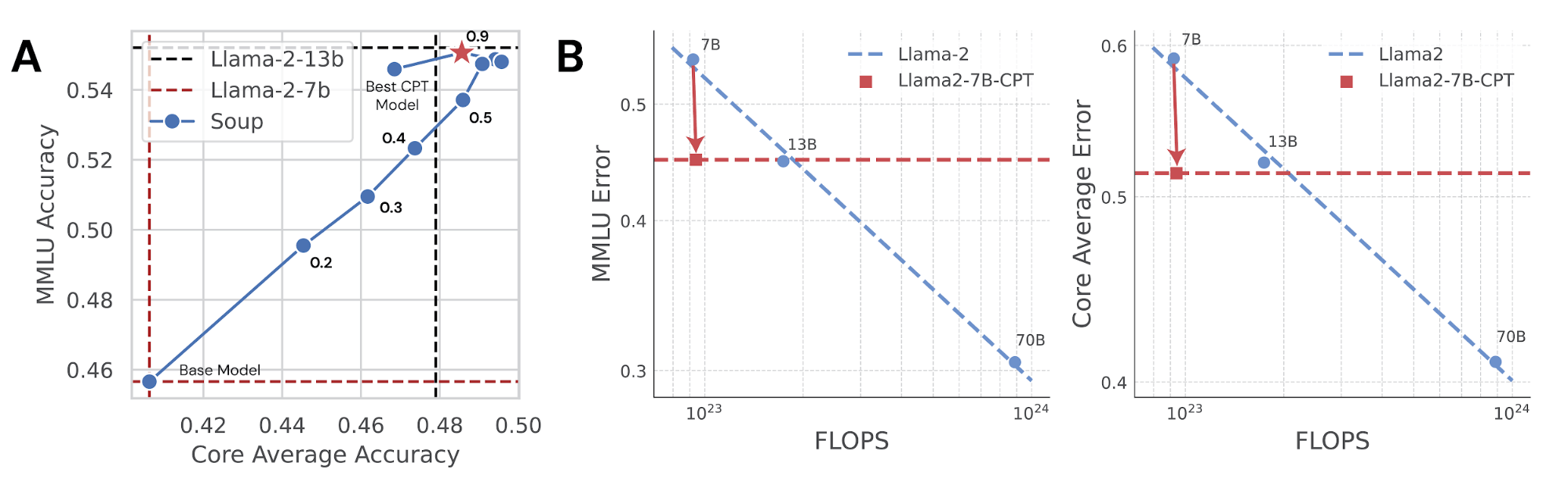
模型的遗忘问题可以通过简单的权重平均(模型soupping)来缓解。
-
CPT的成功依赖于原始预训练数据的组合,新的高质量数据集可以显著改善模型性能。
延伸解读
持续预训练的重要性
持续预训练(CPT)为大型语言模型(LLM)提供了一种有效的定制方法,尤其是在特定领域的应用中。通过在特定领域的大量文本上进行进一步训练,模型能够获得更丰富的领域知识,从而提升其在该领域的表现。对于希望在特定行业中应用LLM的研究者和开发者来说,理解CPT的过程和方法至关重要。
超参数调整的关键
在进行CPT时,学习率、训练时长和数据混合是三个关键超参数。不同的数据集可能需要不同的学习率和训练时长,合理的调整可以显著提高模型性能。读者在实施CPT时,应重视这些超参数的选择和调整,以确保模型能够充分利用特定领域的数据。
数据集选择的影响
选择合适的数据集对模型性能至关重要。文章指出,某些数据集可能会降低模型的准确性,因此在进行CPT时,需谨慎评估数据集的质量和适用性。通过有效的数据集组合,可以最大化模型的学习效果,避免不必要的性能损失。
延伸问答
什么是持续预训练(CPT)?
持续预训练(CPT)是通过在特定领域的大量文本上进一步训练预训练模型,以增强模型的领域知识。
CPT与微调有什么区别?
CPT是在大量领域特定文本上进一步训练预训练模型,而微调则是在较小的任务特定数据集上训练模型以执行特定任务。
进行CPT时需要关注哪些超参数?
进行CPT时需要关注学习率、训练时长和数据混合这三个关键超参数。
如何选择有效的数据集以提高模型性能?
选择有效的数据集需要考虑数据的质量和信息密度,某些数据集可能会降低模型的准确性。
模型遗忘问题如何缓解?
模型遗忘问题可以通过简单的权重平均(模型soupping)来缓解。
CPT如何提升小型LLM的表现?
通过合理的超参数调整和数据混合,CPT可以显著提升小型LLM的表现,使其接近大型模型的水平。
