

AI 论文周报丨递归推理方法/轻量级解码器架构/深度卷积神经网络架构……多领域前沿动态一览
HyperAI超神经
·
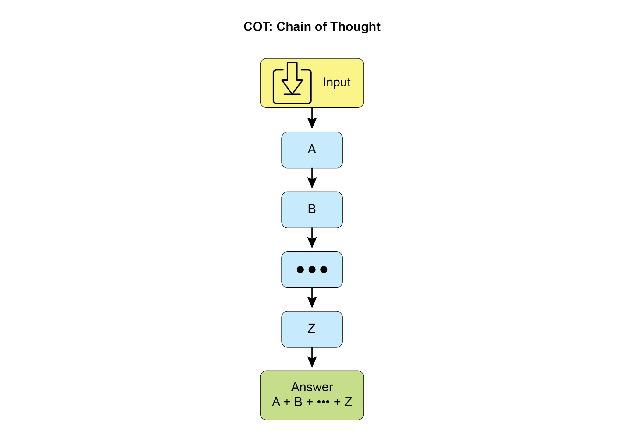
Agent设计模式——第 17 章:推理技术
XINDOO的博客
·

DeepDistill:新型大语言模型推理方法超越蒸馏模型,接近最先进水平
DEV Community
·
查询不一致加权知识库的基于成本的语义
BriefGPT - AI 论文速递
·
