Tensor Core 是专用的矩阵计算单元,利用 MMA 指令实现高效的矩阵乘加运算。FP16 Tensor Core 的吞吐量可达 72.8 TFLOP/s,显著高于 FP32 的 16 TFLOP/s。使用 Tensor Core 时,数据传输速度常成为瓶颈,因此需要优化数据布局和访存策略。CUDA 的 wmma API 简化了 Tensor Core 的使用,而高性能库如 CUTLASS 则能更精细地控制数据布局。
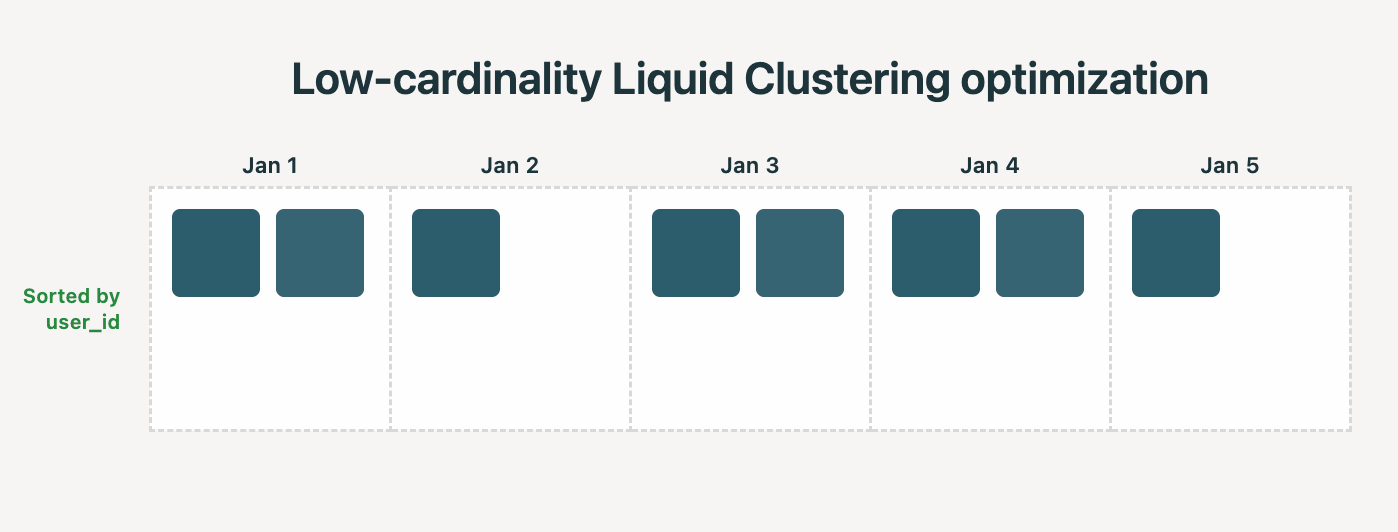
液态聚类是现代湖仓的数据布局标准,解决了传统分区的小文件和过度分区问题。它支持动态调整聚类键和行级并发,优化查询性能。与分区相比,液态聚类在处理高基数列时表现更佳,并支持元数据操作。案例分析表明,液态聚类显著提高了数据处理效率,减少了存储空间。
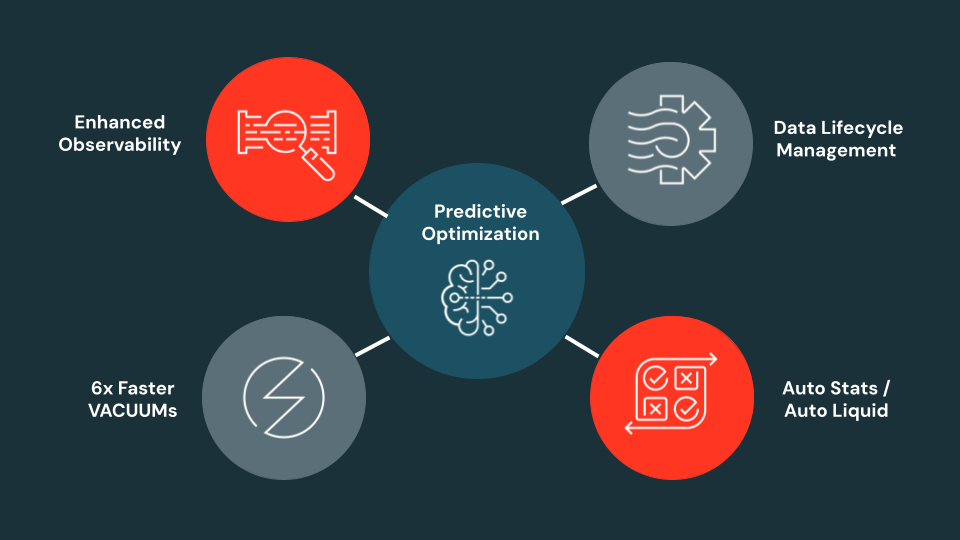
预测优化(PO)通过自动分析数据写入和查询,持续优化数据布局,减少存储占用并提升查询性能。到2025年,PO将成为默认功能,支持自动统计、快速清理和液态聚类,简化手动维护。未来还将推出自动行删除和增强可观察性,进一步提升数据管理效率。
这篇文章探讨了SIMD编程的设计模式,强调数据布局的重要性,提出SoA(结构数组)相较于AoS(数组结构)的优势。介绍了无分支条件赋值的mask + blend方法,以及pshufb指令在字节查表和前缀和实现中的应用。最后,讨论了AVX-512的新特性和跨平台的SIMD策略,建议使用Google Highway库进行跨平台开发。
本研究提出了一种名为PDX的数据布局,旨在加速向量的精确和近似相似性搜索。通过逐维搜索策略和新型维度修剪算法,PDX显著提升了搜索效率,特别适用于频繁更新的向量数据库。
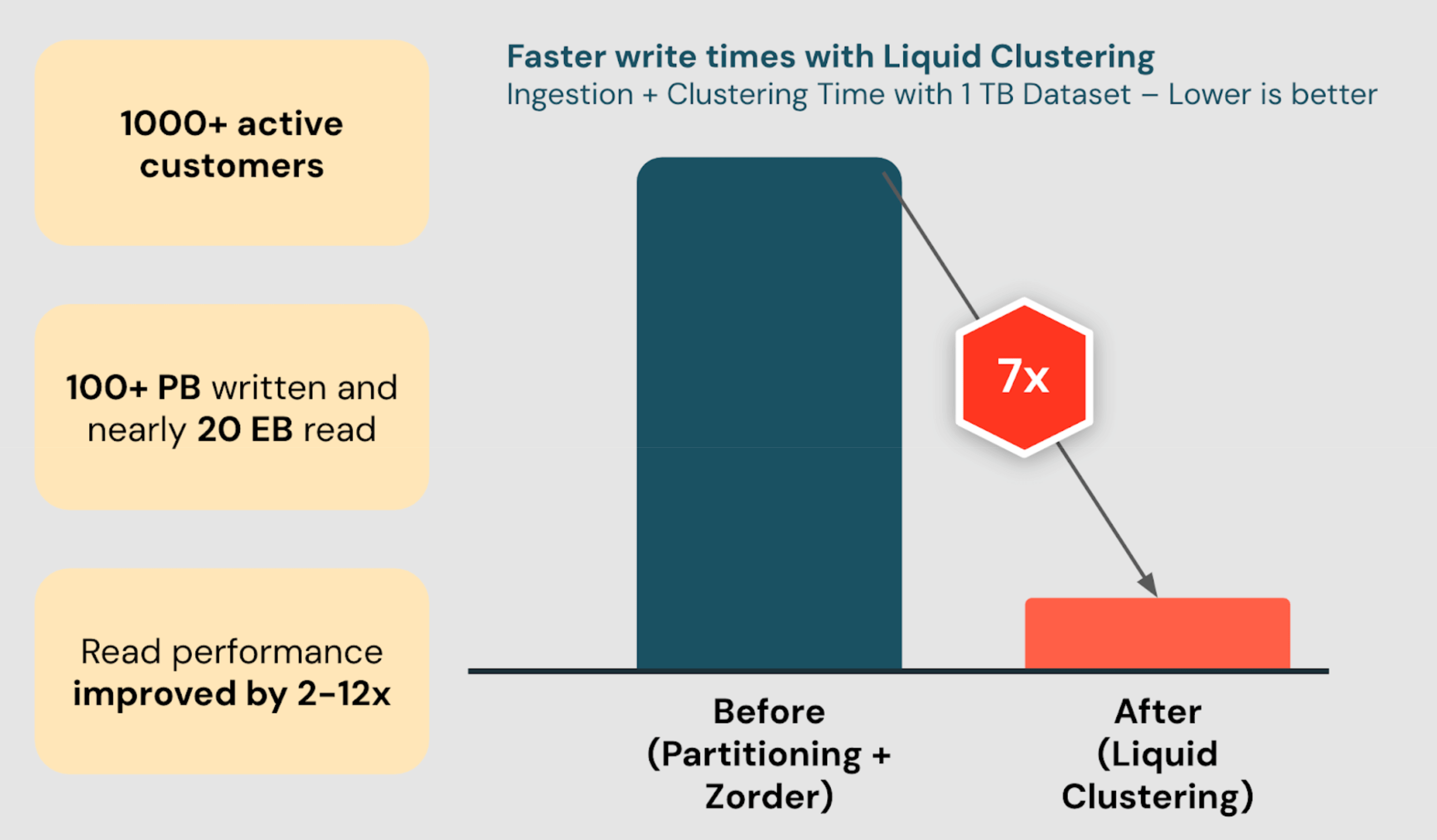
Unity Catalog的预测优化(PO)通过智能优化数据布局,实现了查询速度提升20倍和存储成本降低2倍。自推出以来,已有2400多家客户自动优化数据布局,处理约14PB数据,显著节省存储成本。PO简化了表管理,提升了查询性能,降低了维护工作量。
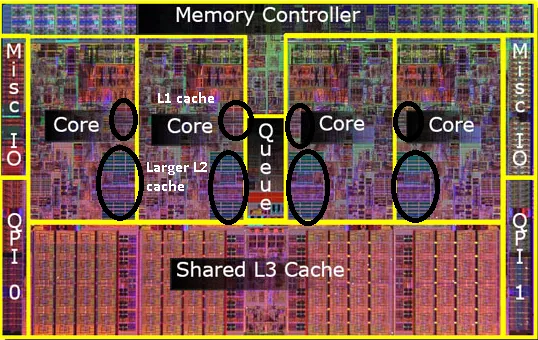
现代多核处理器的缓存机制提升了程序性能,但伪共享问题会降低缓存效率。伪共享发生在多个线程访问同一缓存行的不同变量时,导致频繁的缓存失效。为避免伪共享,可通过变量对齐、分散变量、使用原子变量和绑定CPU核心等方法进行优化。此外,单线程程序也需优化数据布局以提高缓存命中率。
数据智能平台Databricks推出Delta Lake液体聚类正式版,取代了表分区和ZORDER,提供最佳查询性能。液体聚类简化了数据布局决策,允许随分析需求演变。已有数百个客户认可,提高读取性能2-12倍。突破性技术,提供更好的写入和读取性能。可在Delta Lake中使用。
完成下面两步后,将自动完成登录并继续当前操作。