
宣布液体聚类正式发布
内容提要
数据智能平台Databricks推出Delta Lake液体聚类正式版,取代了表分区和ZORDER,提供最佳查询性能。液体聚类简化了数据布局决策,允许随分析需求演变。已有数百个客户认可,提高读取性能2-12倍。突破性技术,提供更好的写入和读取性能。可在Delta Lake中使用。
关键要点
-
Databricks推出Delta Lake液体聚类正式版,取代表分区和ZORDER,提供最佳查询性能。
-
液体聚类简化数据布局决策,允许根据分析需求演变重新定义聚类键,无需数据重写。
-
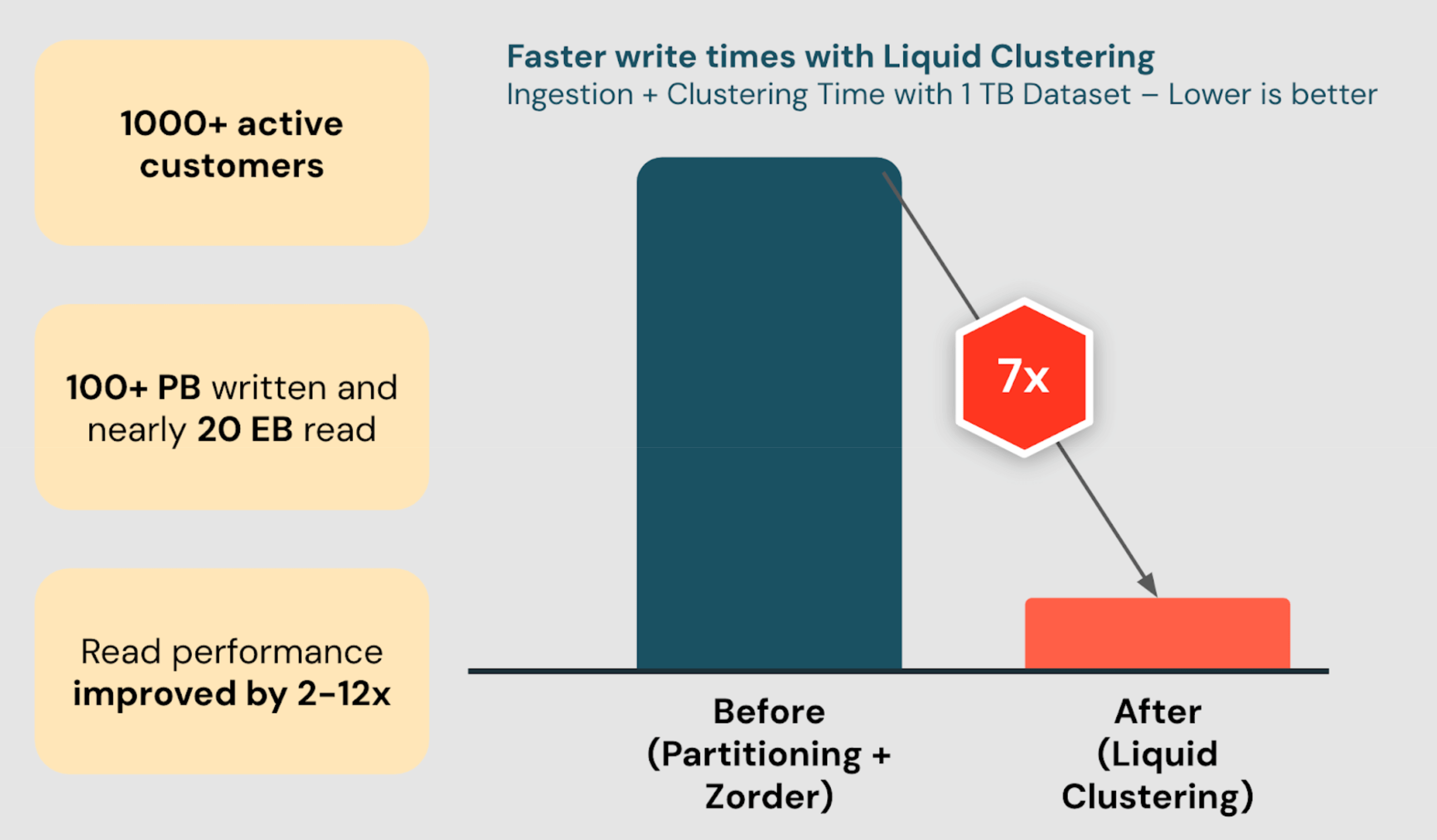
已有数百个客户使用液体聚类,读取性能提高2-12倍。
-
传统方法难以管理,灵活性差,缺乏通用策略。
-
选择分区列的过程复杂,错误选择会导致读取速度慢和查询性能差。
-
ZORDER技术写入成本高,无法增量处理,导致更长的聚类作业和更高的计算成本。
-
液体聚类通过自动调整数据布局,解决了传统方法的挑战,提供更好的写入和读取性能。
-
使用液体聚类简单,只需定义聚类列即可。
-
液体聚类提供快速写入,优化数据布局,降低成本。
-
DatabricksIQ提供记录级并发支持,客户无需依赖分区来实现并发。
-
客户无需微调数据布局即可获得性能提升,许多客户赞扬其简单性和灵活性。
-
液体聚类在DBR 15.2中正式可用,用户可快速启用。
延伸问答
液体聚类的主要功能是什么?
液体聚类简化了数据布局决策,提供最佳查询性能,允许根据分析需求演变重新定义聚类键,无需数据重写。
液体聚类如何提高查询性能?
液体聚类通过自动调整数据布局,提供更好的写入和读取性能,客户的读取性能提高了2-12倍。
与传统的分区和ZORDER方法相比,液体聚类有哪些优势?
液体聚类提供更高的灵活性和简化的管理,避免了复杂的分区策略和高写入成本,且支持增量处理。
如何在Delta Lake中启用液体聚类?
用户可以在DBR 15.2中快速启用液体聚类,只需定义聚类列即可。
液体聚类对数据写入有什么影响?
液体聚类提供快速写入,优化数据布局,降低写入成本,写入速度比传统方法快7倍。
客户对液体聚类的反馈如何?
许多客户赞扬液体聚类的简单性和灵活性,认为它显著提高了查询性能和数据处理效率。
