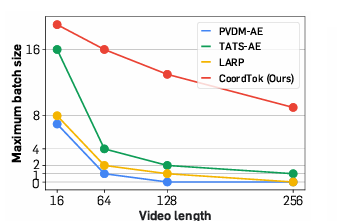
研究人员提出了CoordTok,一种高效的视频标记器,能够有效处理长视频,降低计算成本和内存需求。该方法通过将视频分解为时空块,并利用基于坐标的表示,显著提升了重建质量和效率。然而,CoordTok在处理动态视频时仍需改进。
ModelScopeT2V是一个文本到视频合成模型,通过时空块确保帧生成和运动过渡的一致性。该模型适用于不同帧数量的图像-文本和视频-文本数据集,具有17亿参数,其中5亿参数用于时序能力。在三个评估指标上表现出优越性能,优于现有方法。
完成下面两步后,将自动完成登录并继续当前操作。