
CoordTok:可扩展的视频标记器,可学习从基于坐标的表示到输入视频的相应块的映射
内容提要
研究人员提出了CoordTok,一种高效的视频标记器,能够有效处理长视频,降低计算成本和内存需求。该方法通过将视频分解为时空块,并利用基于坐标的表示,显著提升了重建质量和效率。然而,CoordTok在处理动态视频时仍需改进。
关键要点
-
CoordTok是一种高效的视频标记器,能够处理长视频,降低计算成本和内存需求。
-
视频标记的挑战在于将视频分解为更小的、有意义的部分,尤其是长视频。
-
现有工具难以有效处理大型视频数据集,无法充分利用时间连贯性。
-
早期方法逐帧压缩视频,忽略了帧之间的自然连续性,降低了有效性。
-
CoordTok通过基于坐标的表示学习映射,允许直接在长视频上训练大型标记器模型。
-
该方法将视频编码为分解的三平面表示,降低内存和计算成本,同时保持视频质量。
-
引入分层架构以高效处理视频,掌握局部和全局特征。
-
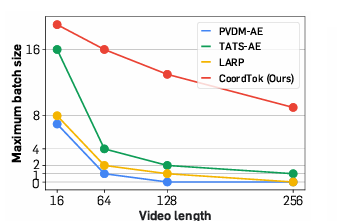
CoordTok在处理128帧视频时,标记数量显著少于基线方法,且重建质量相似。
-
通过微调模型,重建质量得到进一步改善,内存使用量降低50%。
-
尽管CoordTok在长视频处理上表现出色,但在动态视频处理上仍需改进。
延伸解读
CoordTok的优势与应用前景
CoordTok通过将视频分解为时空块,显著降低了长视频处理的计算成本和内存需求。这一创新方法不仅提高了视频重建的质量,还为视频生成模型的训练提供了新的思路,尤其适用于需要处理大量视频数据的领域,如影视制作和在线教育。
动态视频处理的挑战
尽管CoordTok在长视频处理上表现出色,但在动态视频的处理能力上仍存在不足。这意味着在快速变化的场景中,CoordTok可能无法有效捕捉细节和动作。因此,未来的研究需要关注如何增强其在动态视频中的应用能力,以满足更广泛的需求。
技术限制与改进方向
CoordTok的成功依赖于其分层架构和基于坐标的表示,但在处理复杂场景时仍可能面临挑战。研究人员建议未来可以探索使用多个内容平面或自适应方法,以进一步提升模型的灵活性和准确性。这些改进将有助于拓展CoordTok的应用范围。
延伸问答
CoordTok的主要功能是什么?
CoordTok是一种高效的视频标记器,能够处理长视频,降低计算成本和内存需求。
CoordTok如何提高视频重建质量?
CoordTok通过引入分层架构和基于坐标的表示,能够更有效地处理时空块,从而提高视频重建质量。
CoordTok在处理长视频时的优势是什么?
CoordTok能够将长视频分解为时空块,显著降低内存和计算成本,同时保持视频质量。
CoordTok在动态视频处理上存在哪些不足?
尽管CoordTok在长视频处理上表现出色,但在动态视频处理方面仍需改进。
CoordTok如何减少视频标记的数量?
CoordTok将128帧视频编码为1280个标记,而基线方法需要6144或8192个标记,显著减少了标记数量。
CoordTok的微调策略有什么效果?
通过微调模型,CoordTok的重建质量得到进一步改善,内存使用量降低50%。
