

哪个AI实时语音技术平台更好?如何评估AI实时语音技术效果
实时互动网
·

通过ecdysis剥离旧代码:Cloudflare中Rust服务的优雅重启
The Cloudflare Blog
·

AI 可观测性:公共部门任务弹性的支柱
Elastic Blog
·

Workers如何驱动我们的内部维护调度管道
The Cloudflare Blog
·

亚马逊与谷歌的新云连接工具可能更容易应对服务中断
The Verge
·

Weekly Issue-《芯片制造:光刻巨头 ASML 传奇之路》
Yiran's Blog
·
我在Autodesk的职业回顾
Henry Z's blog
·


团队基准评估的五步运营成熟度模型
The New Stack
·

如何在事件发生时简化沟通
The New Stack
·

SLO指标:提升服务可靠性的实用指南
DEV Community
·

如何使用Grafana Cloud合成监控执行Ping检查
engineering on Grafana Labs
·

追踪Node.js中的高内存使用
DEV Community
·
提升可观察性实践 — 第1部分
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
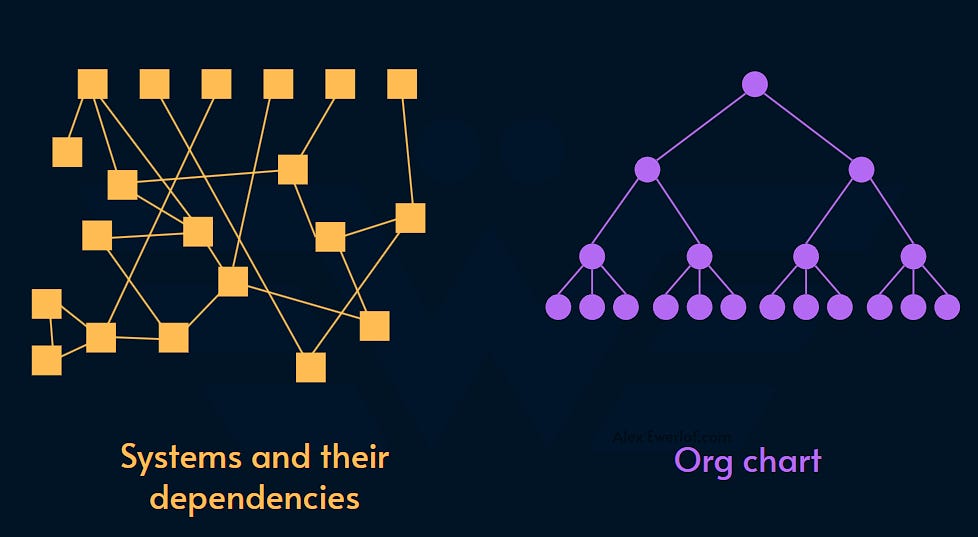
组织架构
Alex Ewerlöf Notes
·
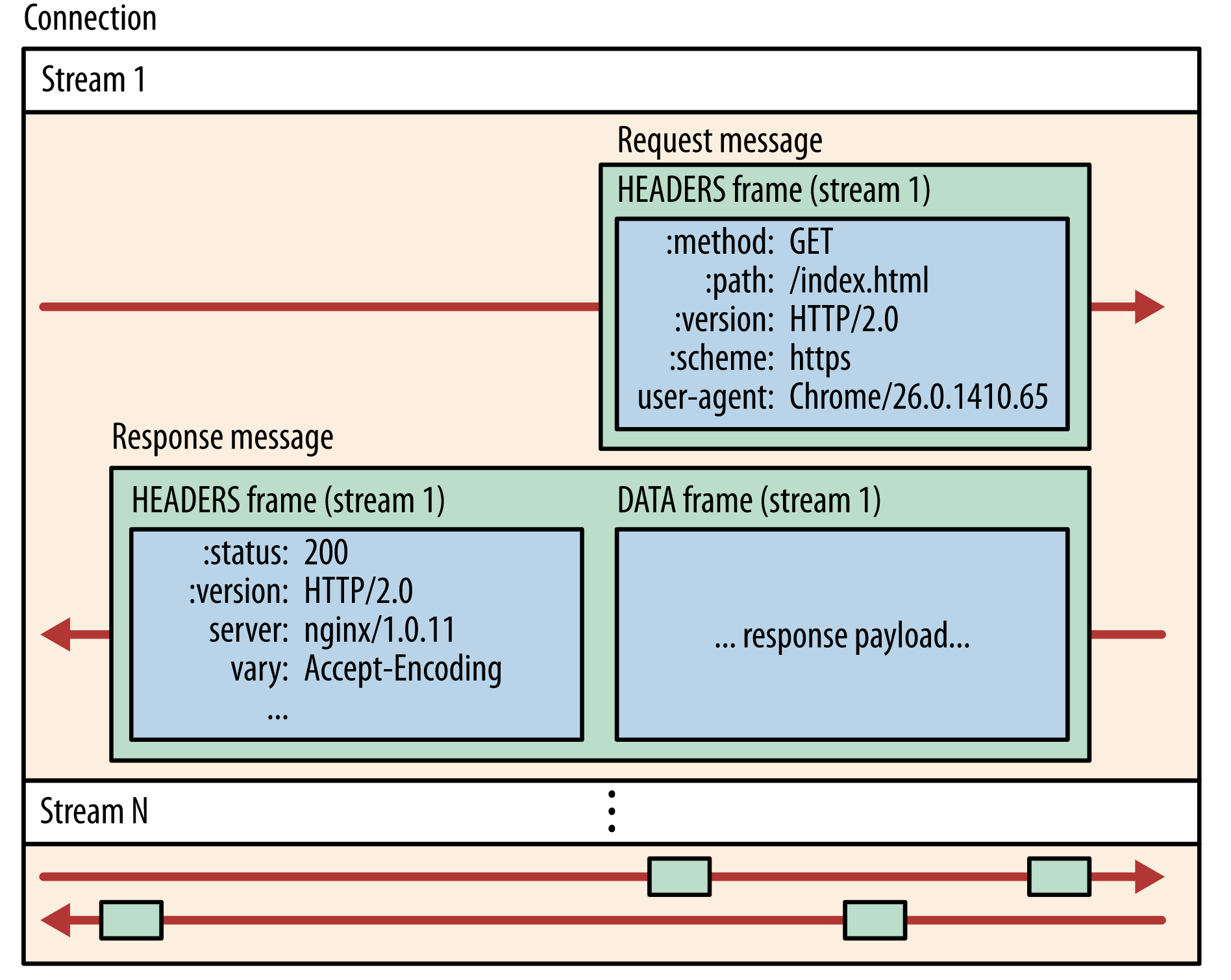
gRPC 系列——grpc 超时传递原理
小米信息部技术团队
·
