
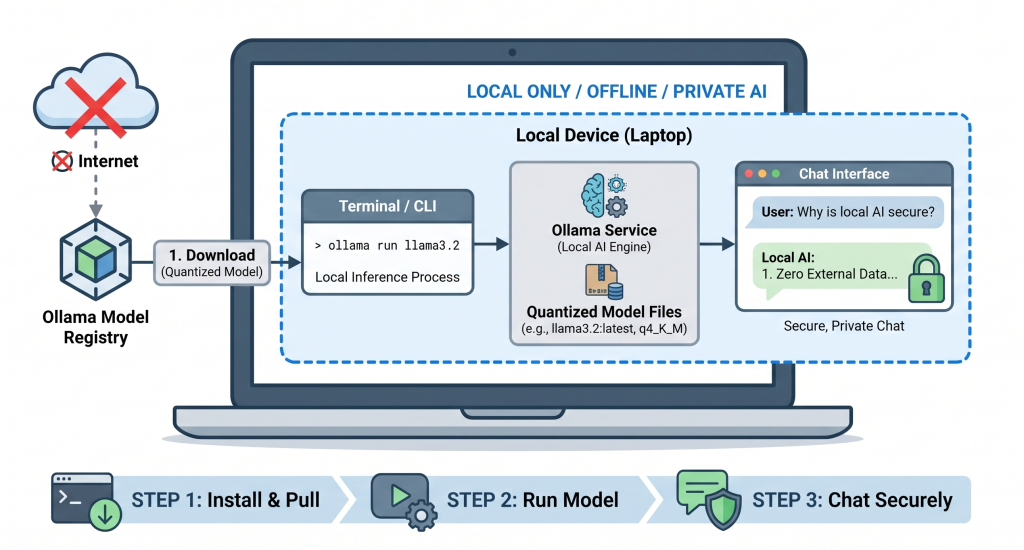
在15分钟内使用Ollama运行本地AI模型
MachineLearningMastery.com
·

如何使用JavaScript构建基于浏览器的PDF图像提取工具
freeCodeCamp.org
·

本地模型在编码中的可行性
Martin Fowler
·

谷歌Gemma 4 12B的性能几乎与26B基准相当——并可在您的笔记本电脑上运行
The New Stack
·


Agent Framework 接入 Ollama(本地模型实践记录)
dotNET跨平台
·
![技术速递|oBeaver —— 一只可以在你本地机器上运行大语言模型的海狸 [特殊字符]](https://i-blog.csdnimg.cn/img_convert/70160dba46b0d7686e2570f24396f6a9.png)
技术速递|oBeaver —— 一只可以在你本地机器上运行大语言模型的海狸 [特殊字符]
dotNET跨平台
·

如何使用Ollama在本地运行和自定义大型语言模型(LLMs)
freeCodeCamp.org
·


Clawdbot / OpenClaw 是如何记住一切的
INTJer
·
macOS 终端下本地跑 LLM 实测
杜老师说
·

如何在本地运行LLM以与您的文档进行交互
freeCodeCamp.org
·

