文章回顾了作者在2023年对ChatGPT的判断,分析了三年后的实际发展与预测的差异。大部分判断方向正确,但具体数字和速度常常高估或低估。特别是在AGI、模型参数和市场变化方面,展现了乐观与保守并存的态度。作者强调,准确把握方向比具体数字更重要,未来仍需关注分布与不确定性。
文章讨论了KV缓存大小计算器的模型参数,包括每个序列的模型令牌数量、序列数量、KV精度和索引器精度等内容。
本文介绍了Veo Extend API的对接说明,主要用于延展已生成的Veo视频。用户需申请API并提供视频ID和模型参数。支持的模型有veo31-fast和veo31,返回结果与视频相关。延展结果视频可再次延展,但不能使用特定接口处理。计费方面,veo31-fast每次1.20信用,veo31每次7.64信用。接口支持异步回调。
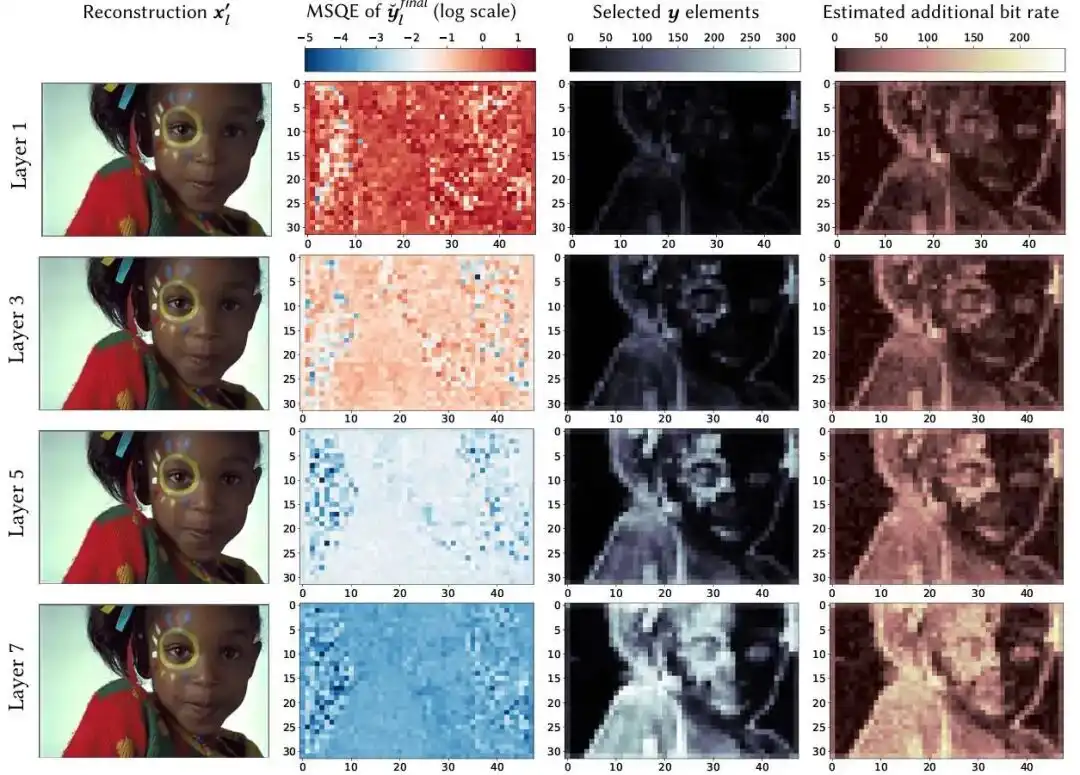
本文提出了一种名为DeepHQ的渐进式图像压缩方法,通过学习量化步长提升压缩效率,并引入选择性压缩,仅编码必要的特征,显著减少模型参数和解码时间。
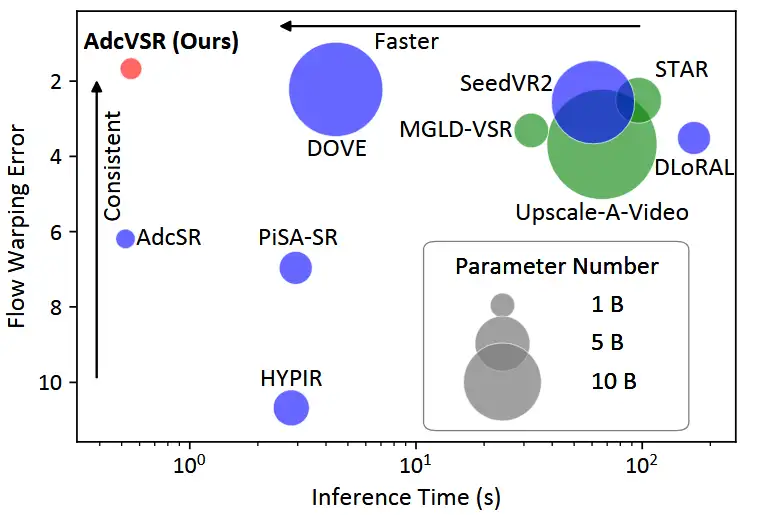
本文提出了一种改进的对抗扩散压缩方法(AdcVSR),用于真实世界视频超分辨率。该方法通过剪枝和轻量级一维卷积,显著降低模型参数和推理时间,同时保持视频质量。实验结果表明,AdcVSR在减少95%参数的同时,实现约8倍的速度提升,优化了细节生成与时域一致性。
模型参数量反映规模和复杂性,通常以十亿为单位。参数是影响预测能力的学习变量。轻量级模型适合个人开发者,高性能模型满足大型企业需求。选择模型时需平衡任务、预算和技术能力。
随着大型语言模型的发展,本文提出了一种动态剪枝方法——指令跟随剪枝,能够根据用户指令动态选择模型参数。该方法通过优化稀疏掩码预测器和LLM,显著提升了推理效率和性能,实验结果在多个评估基准上表现优异。
Qwen2.5-Omni是一个多模态AI模型,支持文本、音频、图像和视频输入,能够生成自然语言的文本和语音响应。适用于实时语音和视频聊天、自然语音生成及复杂指令处理。文章介绍了如何在Python中设置和使用该模型,包括安装必要库和编写生成响应的函数。该模型具有7亿参数,首次运行可能较慢,但后续交互会更快。
本研究提出了一种新策略,将FLIM网络与多层细胞自动机结合,以应对深度学习显著目标检测中对丰富标注数据和复杂网络架构的挑战。该方法在医疗数据集的基准测试中表现优异,显著减少了模型参数并提高了结果质量。
北京大学提出的LIFT框架通过将长文本知识存储在模型参数中,提升了大语言模型对长文本的理解能力。LIFT动态调整模型参数,降低了传统方法的复杂度和存储开销,显著提高了长文本任务的表现。实验结果表明,LIFT在多个基准测试中有效提升了模型准确率,展现出良好的应用前景。
LLM内存计算器是一种工具,用于估算部署大型语言模型所需的GPU内存。用户输入模型参数数量和精度格式(FP32、FP16或INT8),即可计算所需内存。该工具还强调优化技术的重要性,以帮助资源有限的用户有效部署模型,避免内存不足的错误。
本研究探讨了计算最佳规模是否依赖于知识与推理技能,发现不同技能的规模规律显著不同,数据集选择和模型参数的影响可达50%。该研究为大规模语言模型的开发提供了新见解。
本研究提出了一种通用的超参数缩放法则,解决了大型语言模型的超参数优化问题。研究发现,最佳学习率与模型参数和数据规模呈幂律关系,而批次大小主要与数据规模相关。这为模型性能优化提供了有效工具。
满血版DeepSeek运行需要671G内存,单机无法支持。模型参数与内存需求成正比,量化版本可降低内存需求,但精度会下降。
本研究提出了一种新的部分通道机制(PCM)和部分注意力卷积(PATConv),旨在降低模型参数和FLOPs,同时保持准确性和吞吐量。实验结果表明,PATConv有效替代传统卷积,混合网络结构PartialNet在ImageNet-1K和COCO数据集上表现优异。
本研究提出了一种改进的Chinchilla扩展法,通过优化模型参数、训练标记和结构,Morph-1B模型在保持准确性的同时,推理延迟效率提高了1.8倍。
本研究探讨了大型语言模型在扩展行为中的相变现象,重新表述了Transformer架构,发现与文本生成温度和模型参数大小相关的两个显著相变。这些发现有助于估计模型内部维度,并揭示新能力的出现。
本研究提出了一种基于解释引导修剪的通信高效联邦学习方法,旨在降低遥感图像分类中的通信开销。通过层次相关传播策略,识别并传递最相关的模型参数,从而减少模型更新数量,提高全局模型的泛化能力。实验结果表明,该方法显著提升了通信效率和模型有效性。
本研究提出了Proceed框架,以解决时间序列预测中的概念漂移问题。通过估计训练样本与测试样本之间的漂移,及时调整模型参数,实验证明其性能优于现有的在线学习方法。
本研究探讨了多任务微调中的权重确定问题,提出了一种通过贝叶斯模型合并技术重用模型参数的快速预览方法,显著提升了微调效果。
完成下面两步后,将自动完成登录并继续当前操作。