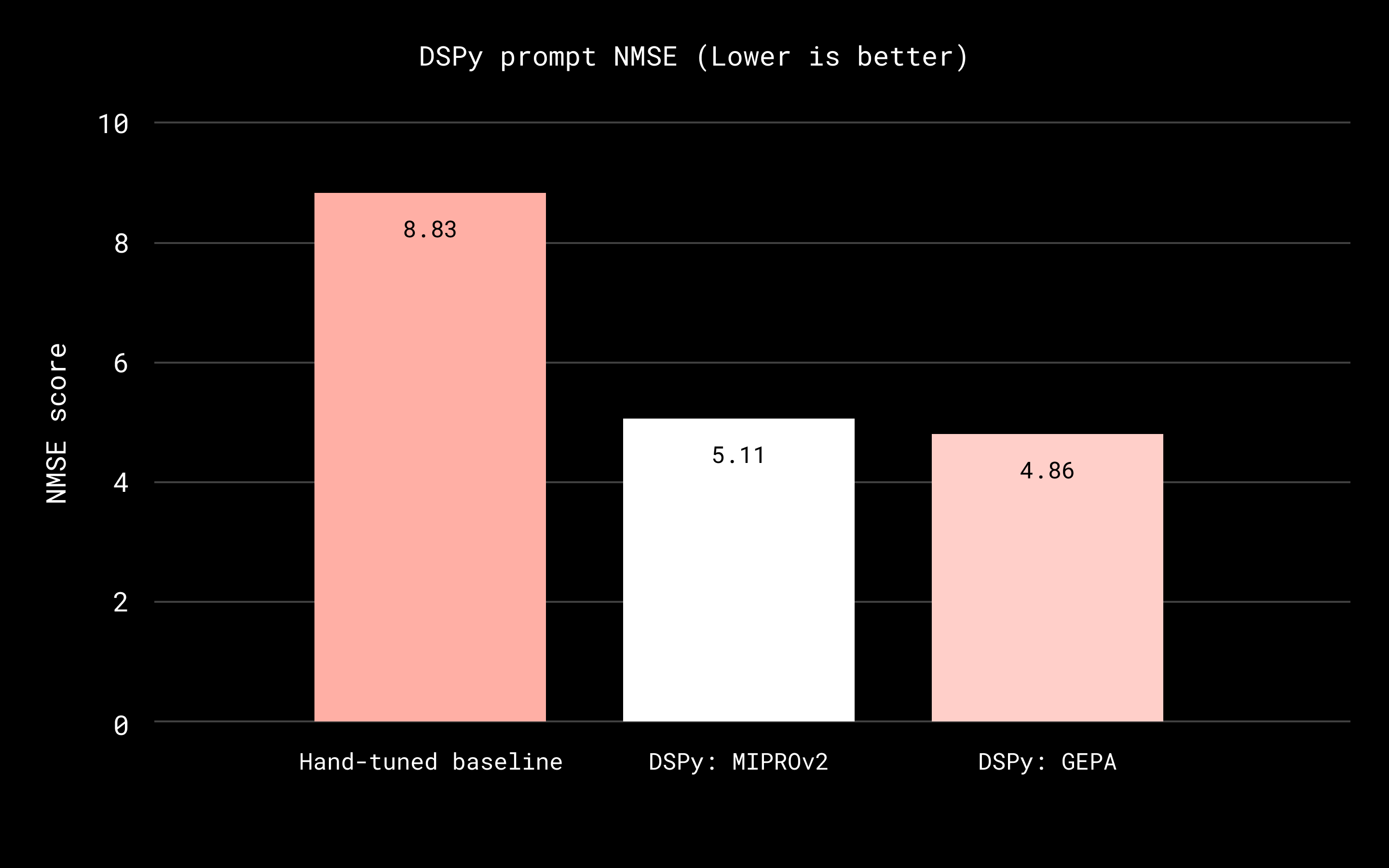
Dropbox Dash整合文件、消息和团队知识,利用DSPy优化相关性判断,提升模型的可靠性和成本效益。通过系统化调整提示,减少与人类评分的偏差,确保输出格式有效,支持大规模数据标注和模型适应。
本研究探讨了ChatGPT等复杂预测模型的可靠性。通过分析10万条关于四位拉美总统的西班牙语评论,发现提示结构的细微变化显著影响情感分类结果,挑战了大型语言模型在分类任务中的稳健性和信任度。
本研究评估了大型语言模型(LLMs)在编程问题解决中的反馈生成能力。结果显示,63%的反馈提示准确且完整,表明LLMs在编程教育中的潜力与局限性,强调提升模型可靠性的重要性。
本研究提出了一种通用的偏差检测框架(G-AUDIT),旨在解决医疗人工智能中的数据集偏差问题。该框架通过分析任务级注释与数据属性的关系,自动量化学习偏差,识别传统方法忽视的细微偏差,从而提升模型的可靠性与安全性。
本研究探讨大型语言模型(LLM)生成高置信度错误输出的现象,称为“LLM幻觉”。研究发现,在低不确定性情况下更难以检测和减轻幻觉,并提出了针对性的减轻策略,以提高模型的可靠性。
本文探讨了人工智能透明性研究中缺失的基础概念,强调不确定性量化的重要性。研究表明,不确定性与反事实可解释性相辅相成,能够通过统一框架增强模型的可靠性和可理解性。
本研究提出了UNIT微调范式,解决了大语言模型在指令微调中的有效性与真实性的平衡问题,显著减少了幻觉现象,提高了模型的可靠性。
本研究探讨了生成模型在医疗影像分析中的隐私风险,特别是文本到图像扩散模型。分析MIMIC-CXR数据集后发现,去标识化痕迹增加了模型的记忆风险,并提出了改善隐私保护和提高模型可靠性的策略。
本研究探讨情感估计系统中注释准确性不足的问题,结合人机协作框架与图像情感模型,分析模型的可靠性及心理因素对信任和注释行为的影响,提出优化建议。
本研究提出DiverseAgentEntropy方法,通过多代理互动量化大型语言模型的不确定性。研究发现,现有模型在面对多样化问题时,常常无法一致地检索正确答案,从而提高了对模型可靠性的预测,并有效识别幻觉现象。
本文提出了一种统一框架,解决大型语言模型(LLM)与人类偏好对齐的复杂性问题。通过将偏好学习策略分解为模型、数据、反馈和算法四个部分,研究揭示了不同方法间的关联性,并提出了改进逻辑一致性的技术,以提高模型的可靠性和一致性。
该研究探讨了大型语言模型(LLM)的事实性问题及其在不同领域应用中的挑战,分析了导致错误的原因,并提出了评估和改进模型事实可靠性的方法。研究还介绍了利用检索增强生成(RAG)系统提高LLM在特定查询中的准确性,强调了知识更新与事实准确性之间的平衡。
本文研究了概念瓶颈模型(CBMs)中输入特征与概念向量的关联性,提出了一种新方法来衡量概念的重要性。通过概率模型、能量模型和递增残差模型等方法,提升了模型的可靠性和解释性,解决了概念完整性和数据处理的挑战。此外,研究展示了如何通过无监督概念发现和大型语言模型来提高模型性能,减少对伪相关性的依赖。
本文探讨了贝叶斯建模在医疗样本预测中的应用,强调其在高风险环境下提高模型可靠性的重要性。研究通过贝叶斯神经网络展示了减少误判和有效识别领域外患者的方法,并提出了基于不确定性引导的主动调查框架,以优化数据收集和提高模型训练效率。
本研究探讨了大型语言模型在非英语语言中的信心估计不足问题。通过多语种信心估计(MlingConf)方法,发现英语在语言无关任务中表现优越,而使用相关语言提示可显著提升语言特定任务的信心估计,从而提高模型的可靠性和准确性。
本文探讨了大型语言模型(LLMs)在不确定性量化和风险评估中的应用,提出了新的评估框架和方法,以提高模型在多选题和高风险领域的可靠性。研究表明,符合性预测与模型准确性密切相关,并提出了风险调整校准方法DwD,以降低决策风险和综合风险,强调了提升模型能力和安全性的重要性。
本研究探讨了大型语言模型(LLM)的可信度评估,包括可靠性、安全性和公平性等关键维度。测试结果显示,更符合人类意图的模型在可信度上表现更佳。研究提出了TrustScore框架,用于评估模型响应与知识的一致性,并探讨了检索增强生成(RAG)系统的潜力,强调提高LLM在实际应用中的可信性的重要性。
本文综述了机器学习模型的对抗攻击及其防御方法,强调模型决策的可解释性和鲁棒性。研究提出了一种基于深度神经网络的对抗样本检测方法,并探讨了对抗攻击对欺诈检测系统的影响,建议改进归因方法以增强模型在安全关键应用中的可靠性。
本文探讨了深度神经网络中的置信度校准问题,提出了温度缩放法和概率校准树等多种校准方法,以提高模型预测的可靠性。研究引入了新的评估指标,揭示了现有校准技术的缺陷,并针对置信度过高和过低提出了相应的校准技术。通过大量实验验证了这些方法的有效性,强调了校准在机器学习任务中的重要性。
本文探讨了大型语言模型(LLM)中的幻觉现象,并提出了多种检测和纠正方法,包括基于不确定性的检测、监督学习和无监督框架。研究表明,这些新方法能有效提高幻觉检测的准确性,增强模型在实际应用中的可靠性。
完成下面两步后,将自动完成登录并继续当前操作。