本研究提出了一种新方法PAINT,通过引入可学习的领域特定提示,解决持续测试中的灾难性遗忘问题,显著提升模型的适应能力。
本研究针对机器学习中的概念漂移问题,提出了无监督漂移采样策略(SUDS)和统一标注数据准确性指标(HADAM),以提升模型的适应能力和标注数据的使用效率。
本研究提出了一种分布自适应学习(DAL)框架,旨在解决开放环境中数据分布演变的跟踪问题。通过编码特征边际分布信息,突破了最优传输的限制,增强了模型的适应能力,实验结果验证了其有效性。
本文提出了一种数据驱动的方法,研究跨语言声学语音相似性,通过深度神经网络训练实现不同声音模型的可比性。研究表明,少重叠语音的语言更易于跨语言传输,单语言模型融合相比单语言识别提高了8%。此外,探讨了低资源语言的翻译和模型适应策略,提出利用相关语言和数据增强的方法以提升多语言模型的适用性。
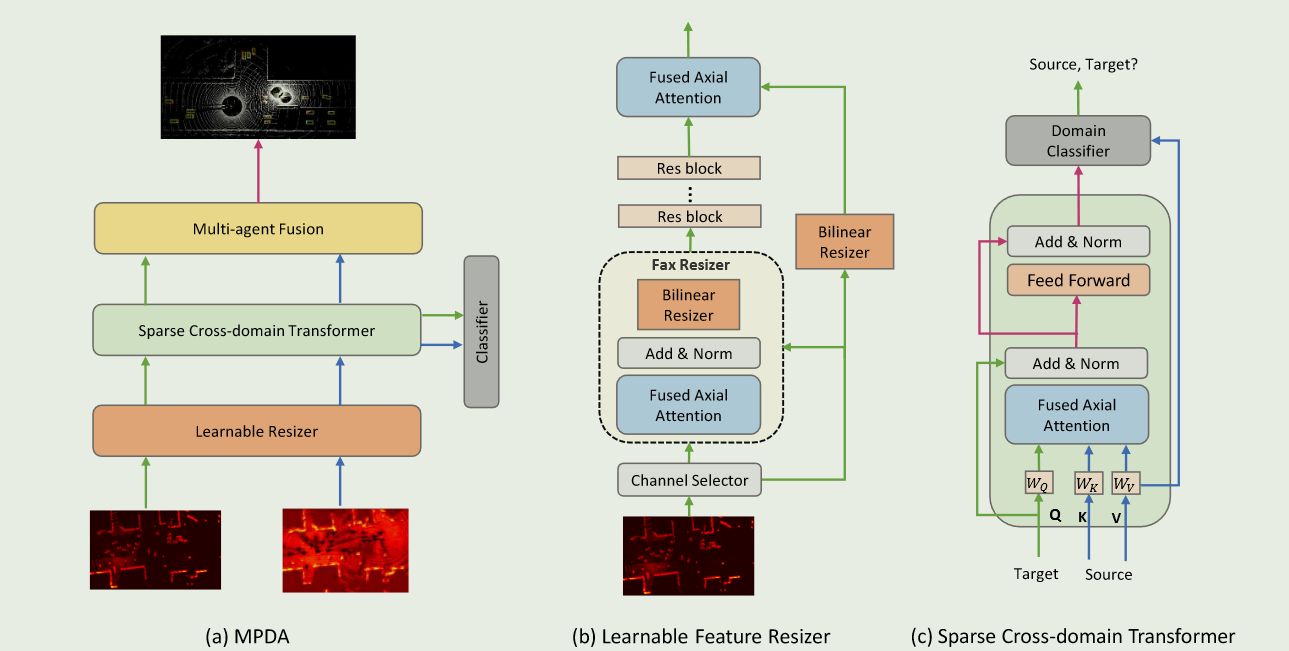
本文介绍了三篇关于多智能体感知的研究,分别解决了领域差距、模型适应和仿真到现实迁移学习问题。这些研究提出了有效的解决方案,对多智能体感知的发展具有重要意义。
完成下面两步后,将自动完成登录并继续当前操作。