Anthropic承认其Claude聊天机器人在法律文件中出现了错误,错误引用了不存在的来源,导致音乐出版商的法律辩护中标题和作者不准确。尽管进行了手动检查,仍未发现这些错误。Anthropic对此表示歉意,并指出这是使用AI工具进行法律引用时的常见问题。
我国法律文件数量激增,传统检索方法面临困难。2024年4月,华宇元典推出“元典问达”智能法律问答引擎,利用大模型技术支持自然语言提问,快速生成法律分析报告,提高法律研究效率。
本研究探讨法律文件因结构复杂和术语专业导致的可读性差问题,识别出常用的可读性指标,发现Flesch-Kincaid年级水平最为普遍,强调需在法律文档可读性评估上达成共识。
本文探讨了新型抽象汇总模型在法律文件摘要中的应用,结合了抽取与生成技术。研究发现,生成模型在摘要质量上优于传统抽取方法,但仍存在信息不一致和虚构的问题,需进一步改进。
本文介绍了AraLegal-BERT模型在阿拉伯法律文件中的应用,显示其在自然语言理解任务上优于传统BERT。研究评估了大型语言模型在法律领域的表现,发现GPT-4表现最佳,但仍有提升空间。基于GPT-3.5的模型在阿拉伯法院判决预测中表现突出,并探讨了法律领域NLP面临的挑战及未来发展方向。
本文探讨了在印度法院判决中使用抽象式摘要模型的可行性,发现其在质量上略优于抽取式模型,但生成的摘要信息常不一致。研究强调了自动摘要在法律文件中的重要性,并提出了多种基于深度学习的自动摘要技术,以提高法律文本的分析效率和公众获取法律信息的能力。
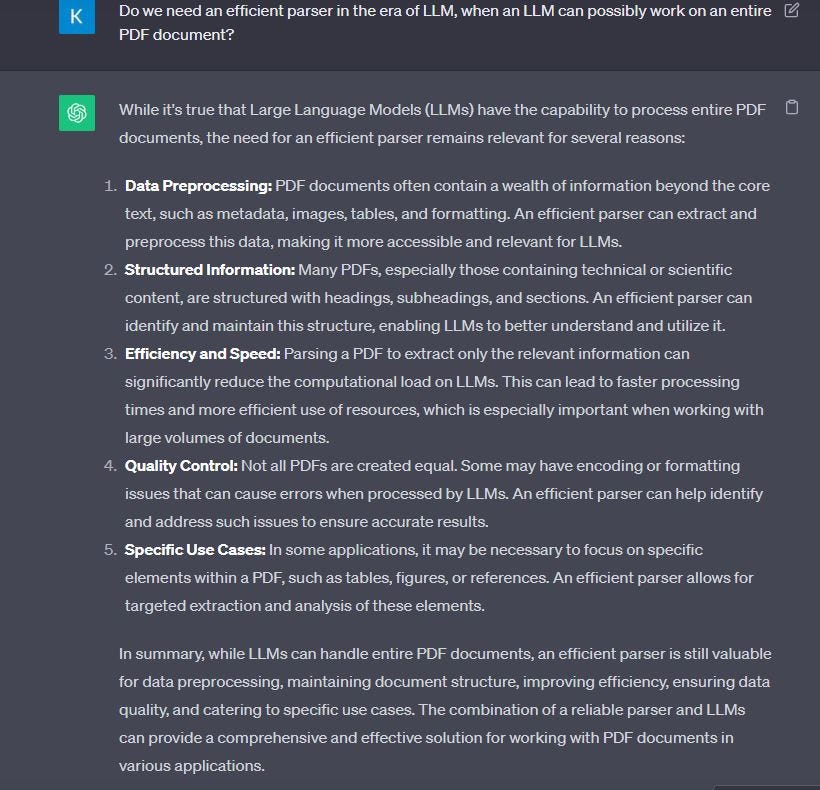
本文讨论了处理复杂PDF文档,特别是法律文件时面临的挑战,包括布局复杂性、字体编码问题和非线性文本存储导致的内容提取困难。尽管大型语言模型(LLMs)功能强大,但在处理长文本时存在局限性,因此需要高效的解析器。LayoutPDFReader工具通过“上下文感知”分块技术,优化信息检索,提升LLM的性能。
本文讨论了期权的设计与实施,强调合理法律文件和条款的重要性。建议创业者遵循成熟的期权方案,确保公平与平衡,避免未来纠纷。期权授予价格应基于市场公允价,离职时需在规定时间内行权。律师的参与能确保文件的严谨性,保护员工权益。
完成下面两步后,将自动完成登录并继续当前操作。