
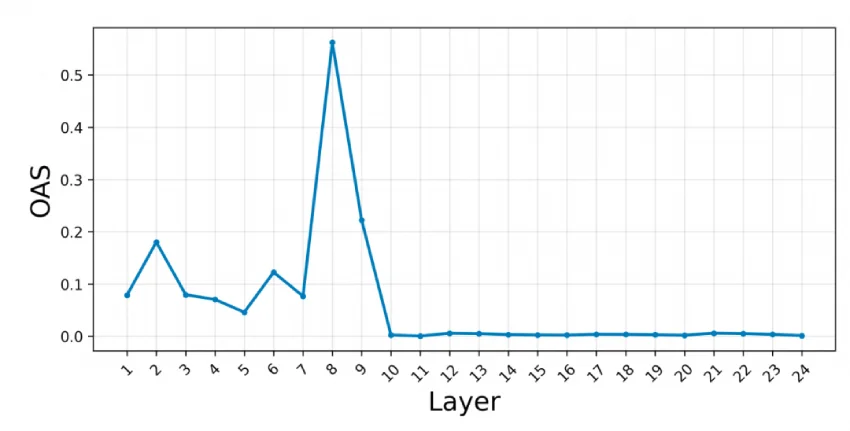

大模型推理路由难题反而催生稀疏注意力?
极道
·

基于长音频编码的分段注意力解码
Apple Machine Learning Research
·

注意力机制之后是什么?这家初创公司表示它已经知道了。
The New Stack
·

Instagram想要垄断你的注意力
The Verge
·

Firefox的新主页小部件帮助我集中注意力
The Verge
·
工作中最稀缺的是什么?
Posts on WKLKEN THINKING
·
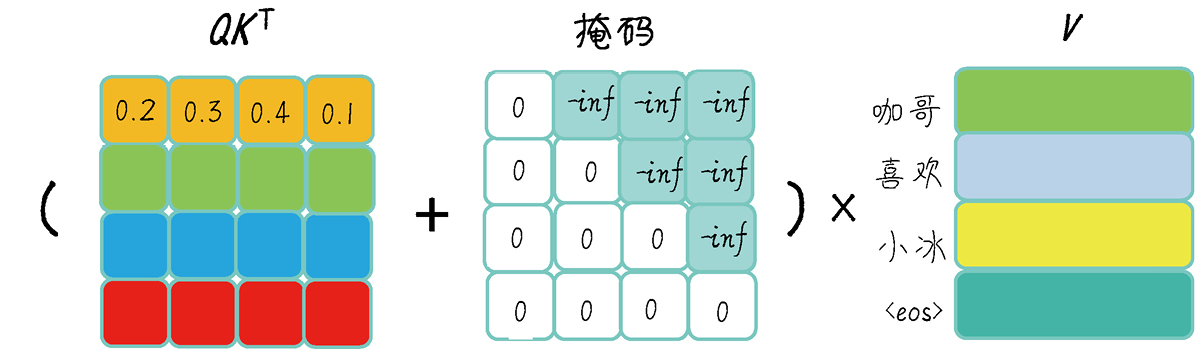

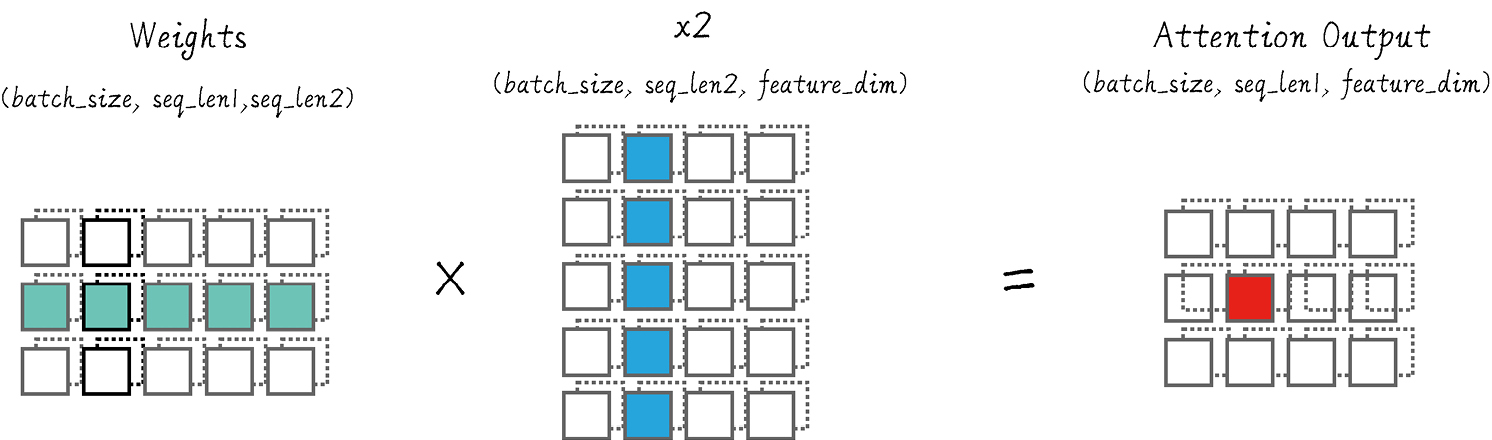
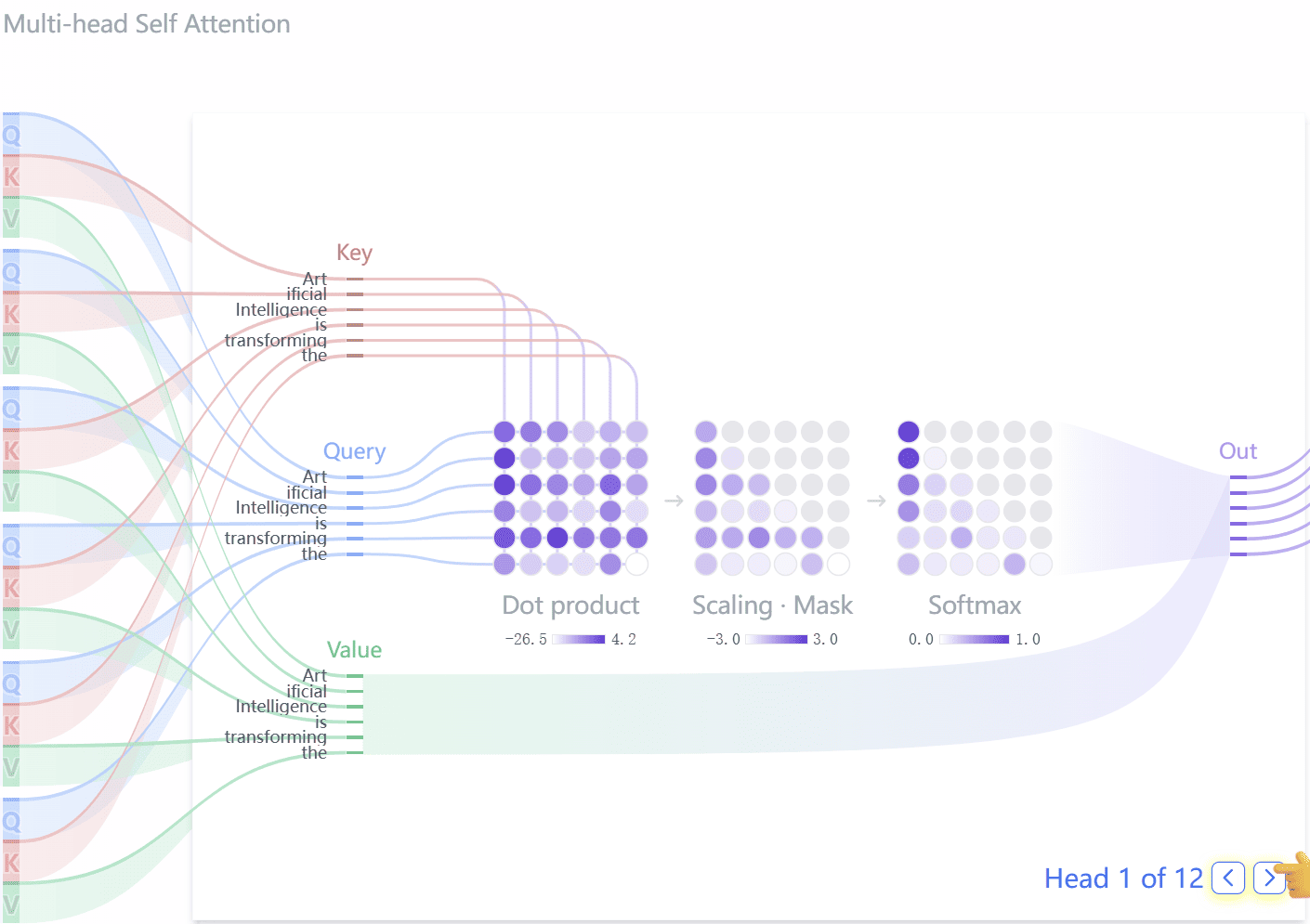
《GPT 图解》笔记:Seq2Seq及点积注意力
Ying’s Blog
·

为什么必须戒短视频
joojenZhou 个人网站
·
