
大语言模型的基石:Transformer 入坑笔记(三) - 注意力机制和 Transformer
内容提要
本文介绍了Transformer模型的注意力机制及其背景。传统的卷积神经网络(CNN)和循环神经网络(RNN)在处理长距离依赖时存在局限,而Transformer通过自注意力机制解决了这些问题。模型使用位置编码来区分词序,核心是通过Query、Key和Value计算注意力权重。多头注意力允许模型并行处理不同关系,增强表达能力。混合专家模型(MoE)通过选择部分专家参与计算,提高了效率和性能。
关键要点
-
传统的卷积神经网络(CNN)和循环神经网络(RNN)在处理长距离依赖时存在局限。
-
Transformer通过自注意力机制解决了长距离依赖的问题,使用位置编码来区分词序。
-
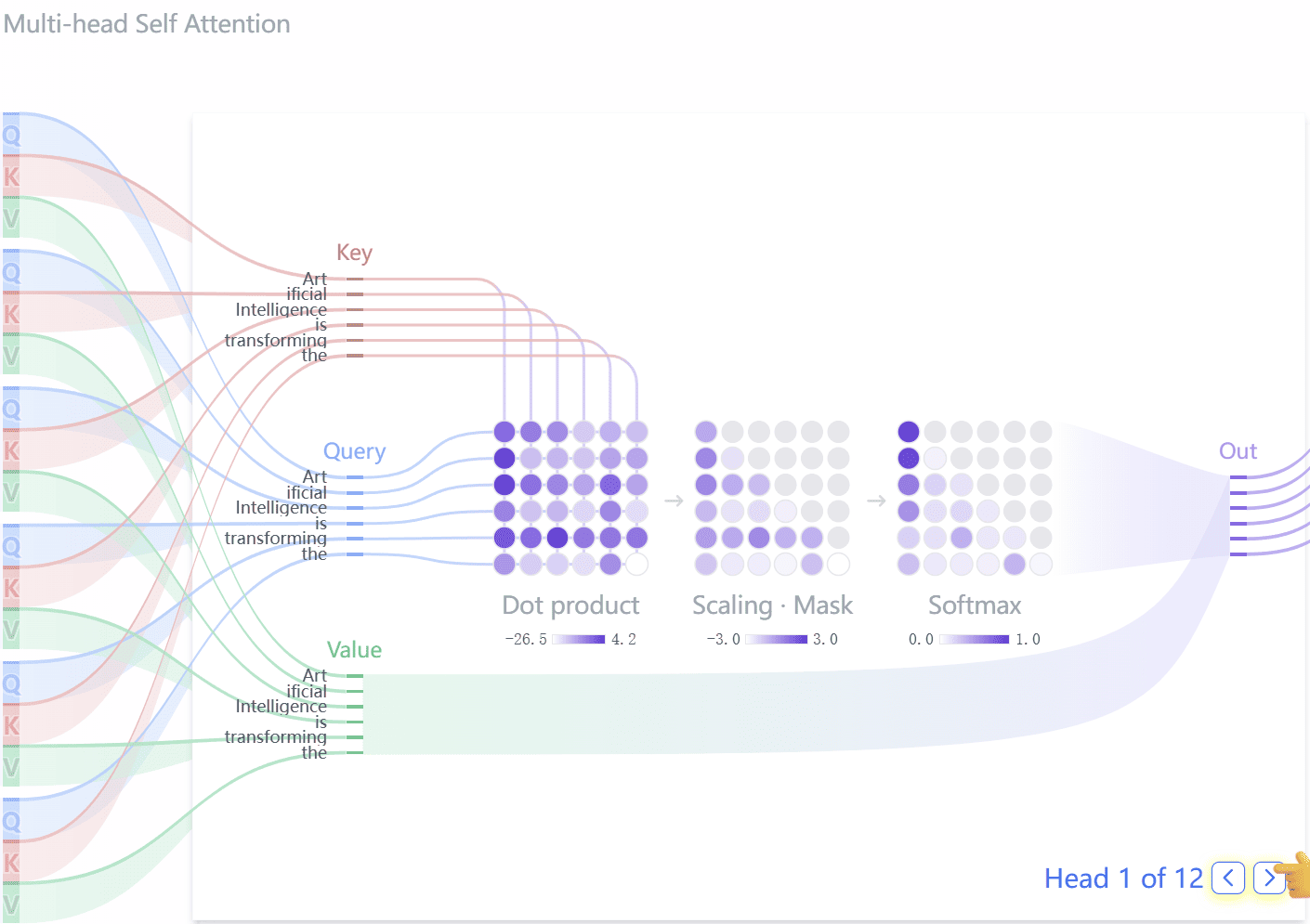
Transformer模型的核心是通过Query、Key和Value计算注意力权重。
-
多头注意力允许模型并行处理不同关系,增强表达能力。
-
混合专家模型(MoE)通过选择部分专家参与计算,提高了效率和性能。
延伸解读
注意力机制的优势
Transformer模型的自注意力机制解决了传统RNN在处理长距离依赖时的局限性。通过并行计算,Transformer能够更高效地捕捉序列中各个词之间的关系,尤其在处理长文本时表现优越。
位置编码的重要性
位置编码在Transformer中至关重要,因为它帮助模型理解词语的顺序。没有位置编码,模型无法区分“我爱你”和“你爱我”这样的句子。因此,设计合理的编码方式是提升模型性能的关键。
混合专家模型的效率
混合专家模型(MoE)通过选择部分专家参与计算,显著提高了模型的计算效率。这种方法不仅减少了每次推理的计算负担,还能在保持模型性能的同时降低资源消耗,适合大规模应用。
延伸问答
Transformer模型如何解决长距离依赖问题?
Transformer通过自注意力机制和位置编码来解决长距离依赖问题,使得模型能够有效处理序列中的信息。
什么是自注意力机制?
自注意力机制是Transformer的核心部分,允许当前Token通过Query与所有Key进行匹配,并根据匹配权重汇总对应的Value。
多头注意力的作用是什么?
多头注意力允许模型并行计算多个注意力头,从而增强模型的表达能力,能够同时关注不同的关系。
位置编码在Transformer中有什么作用?
位置编码用于提供词在序列中的位置信息,帮助模型区分同词不同序的输入。
混合专家模型(MoE)是如何提高效率的?
混合专家模型通过选择部分专家参与计算,减少了每个Token的计算负担,从而提高了模型的效率和性能。
Transformer模型的核心计算是如何进行的?
Transformer模型的核心计算通过Query、Key和Value的线性投影和注意力计算来实现,最终输出经过多头注意力和前馈神经网络处理。
