

MemoryLLM:即插即用的可解释前馈记忆模型用于变换器
Apple Machine Learning Research
·
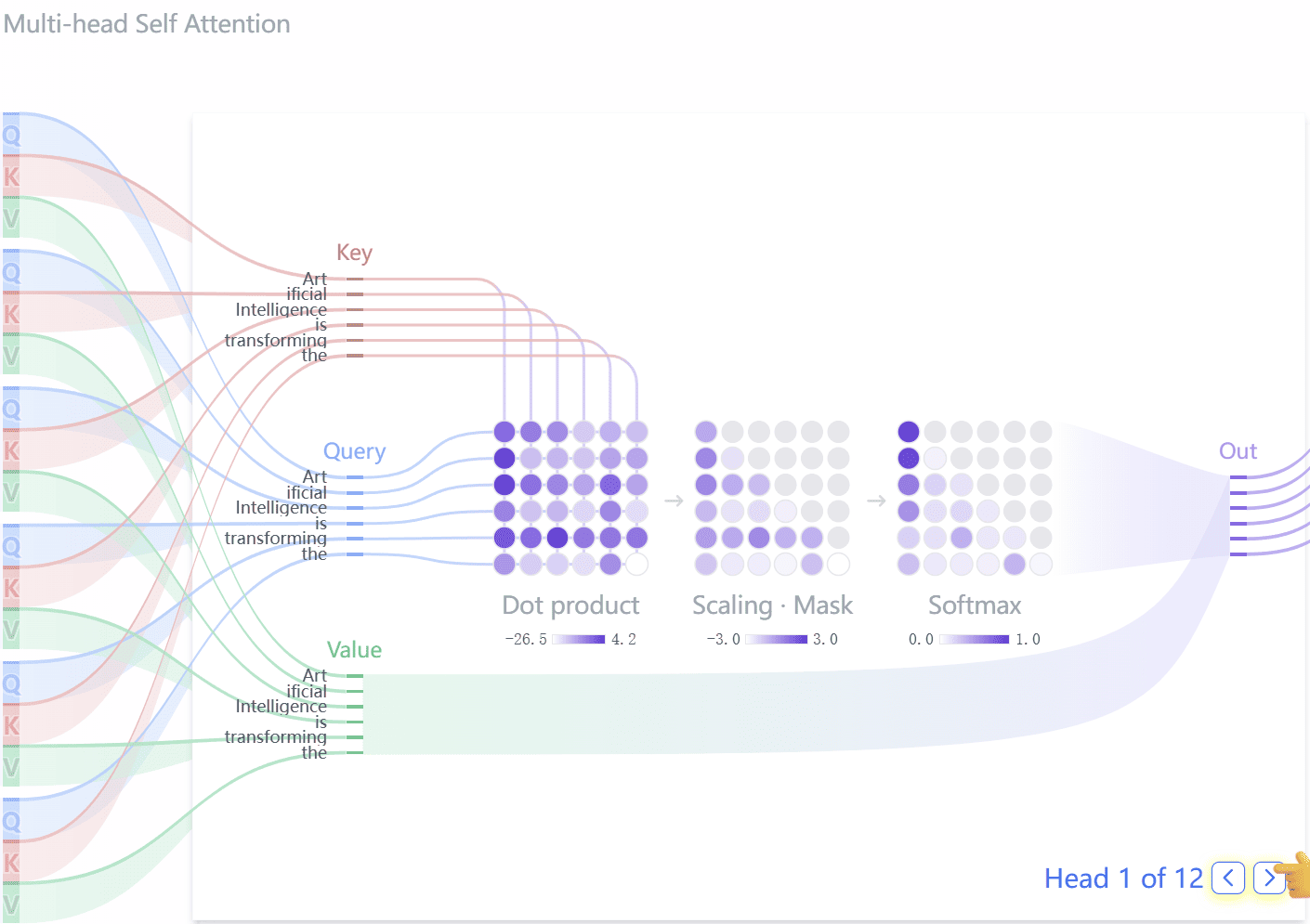
独占自注意力
Apple Machine Learning Research
·

最后一遍学习Transformer
plus studio
·


解码《注意力即全部所需》……
DEV Community
·
