

科技爱好者周刊(第 404 期):你需要知道的 AI 内存知识
阮一峰的网络日志
·

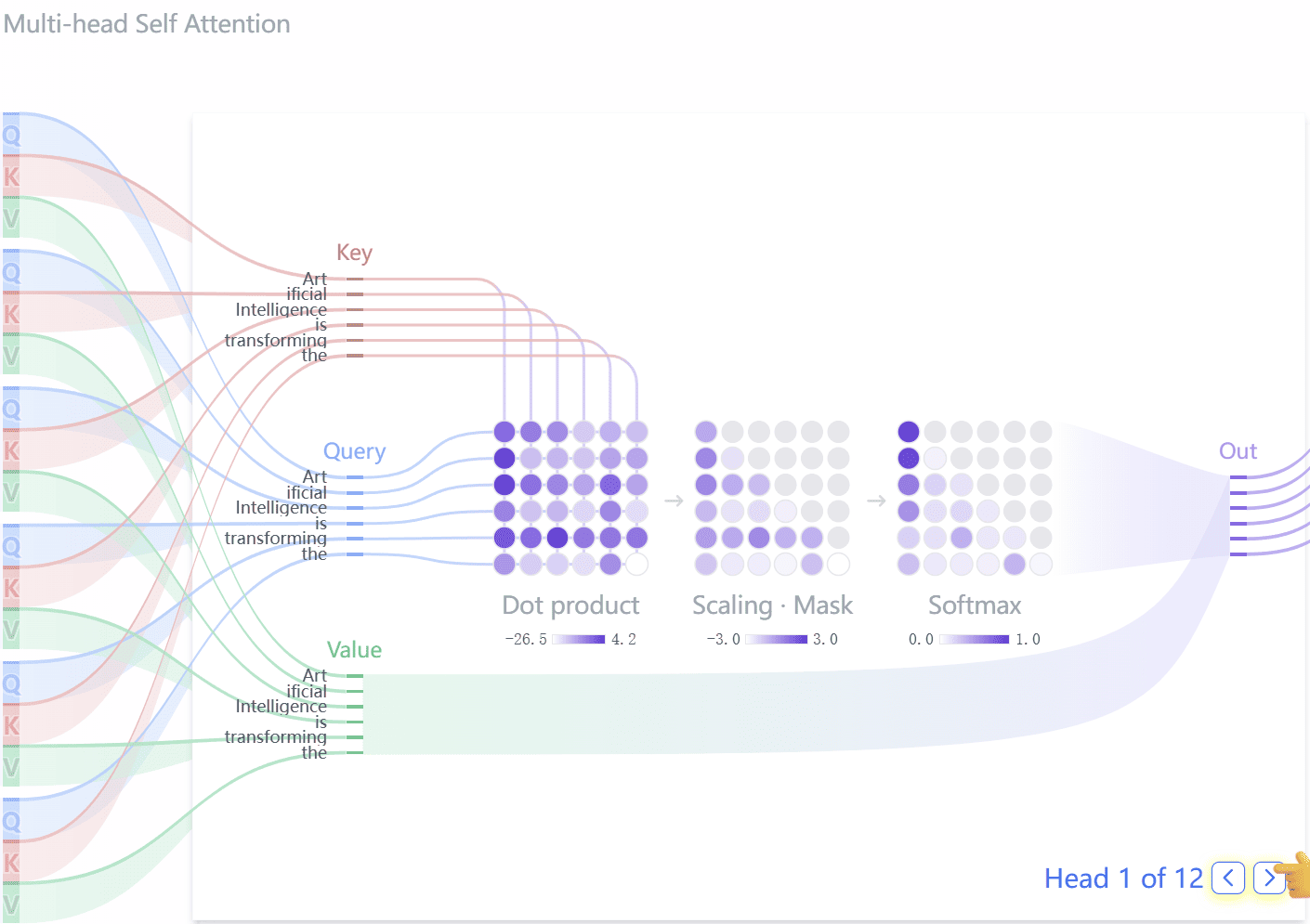
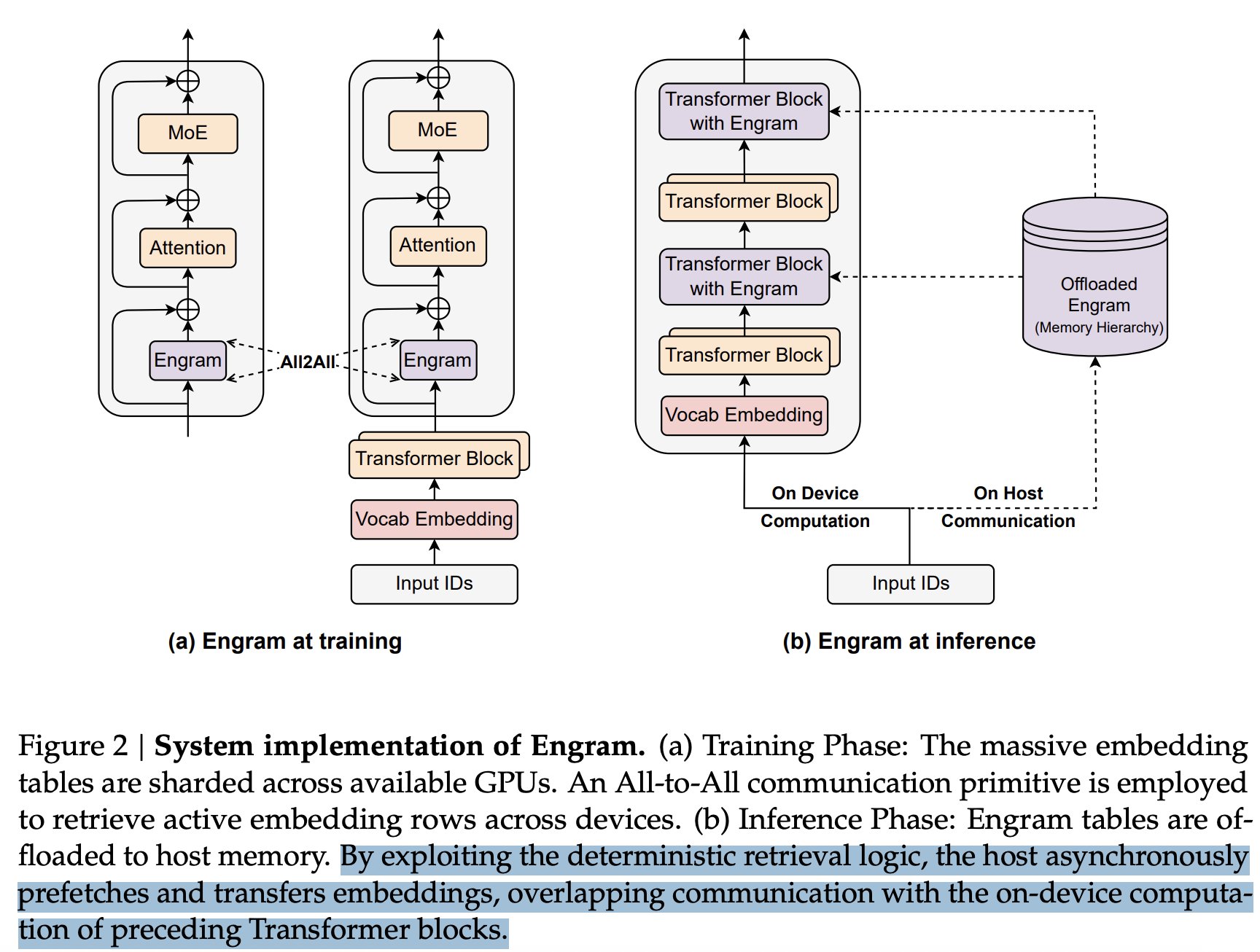
DeepSeek 的 10 万亿美元大战略
宝玉的分享
·

NVIDIA与Mistral AI合作加速新一代开放模型的推出
NVIDIA Blog
·


MoMoE:内存优化的专家混合模型
Nathan Chen
·

NEXA-MOE:一种高效强大的AI,用于在资源紧张的情况下进行科学发现
DEV Community
·

EC-DIT:通过自适应专家选择路由扩展扩散变换器
Apple Machine Learning Research
·


阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节
机器之心
·

通过全局负载均衡提升混合专家模型的性能和特异化程度
Blog on Qwen
·
