
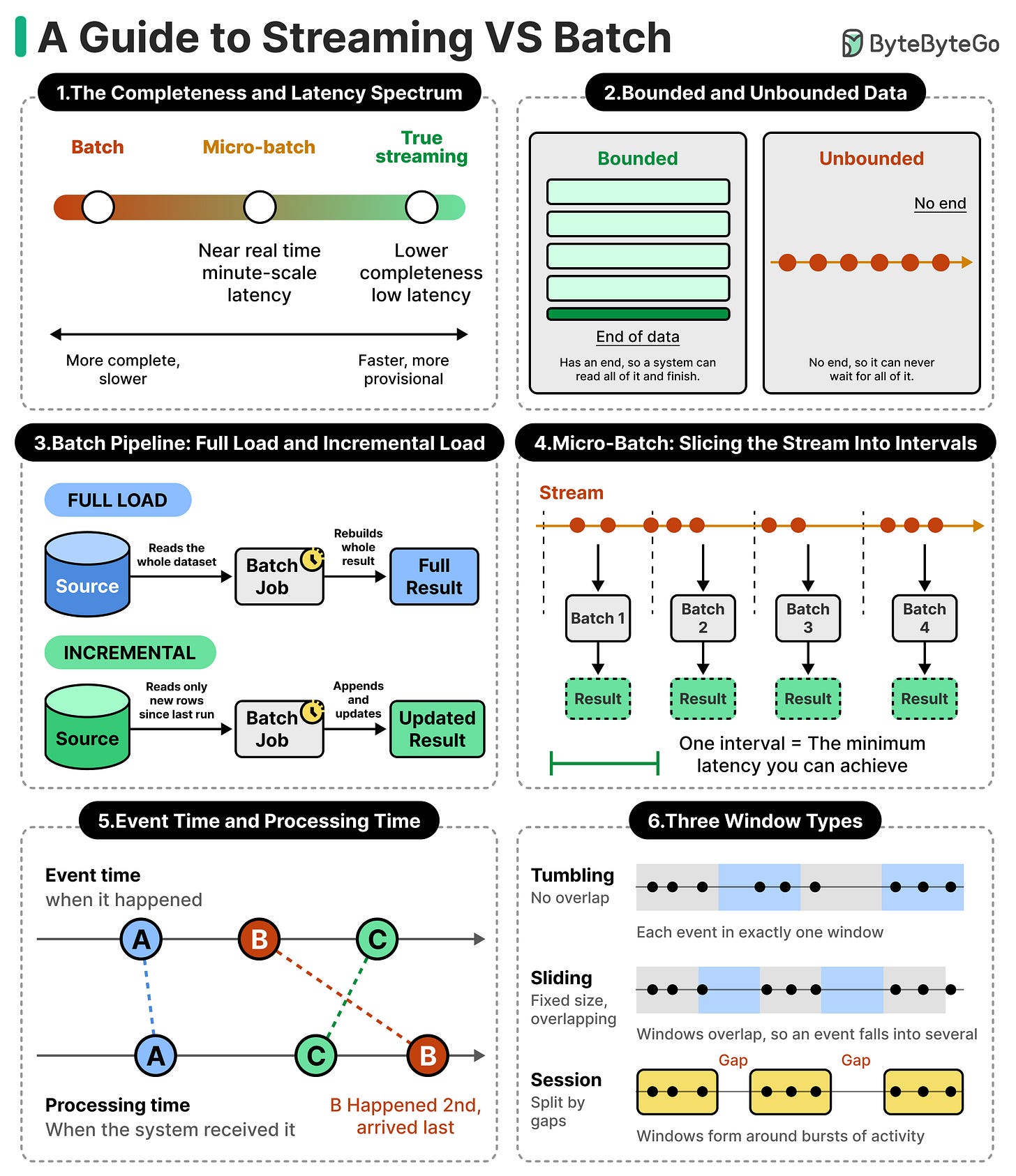
流处理与批处理:数据处理的两种哲学
ByteByteGo Newsletter
·

什么是数据管道架构?
Databricks
·

2026年5月版:新动态
Redis Blog
·

Redis 8.4中的XREADGROUP CLAIM实现单次可靠消费者
Redis Blog
·
无需新硬件的软件解决方案可降低AI的能耗
The New Stack
·

Python中的高效数据处理:批处理与流处理管道解析
freeCodeCamp.org
·
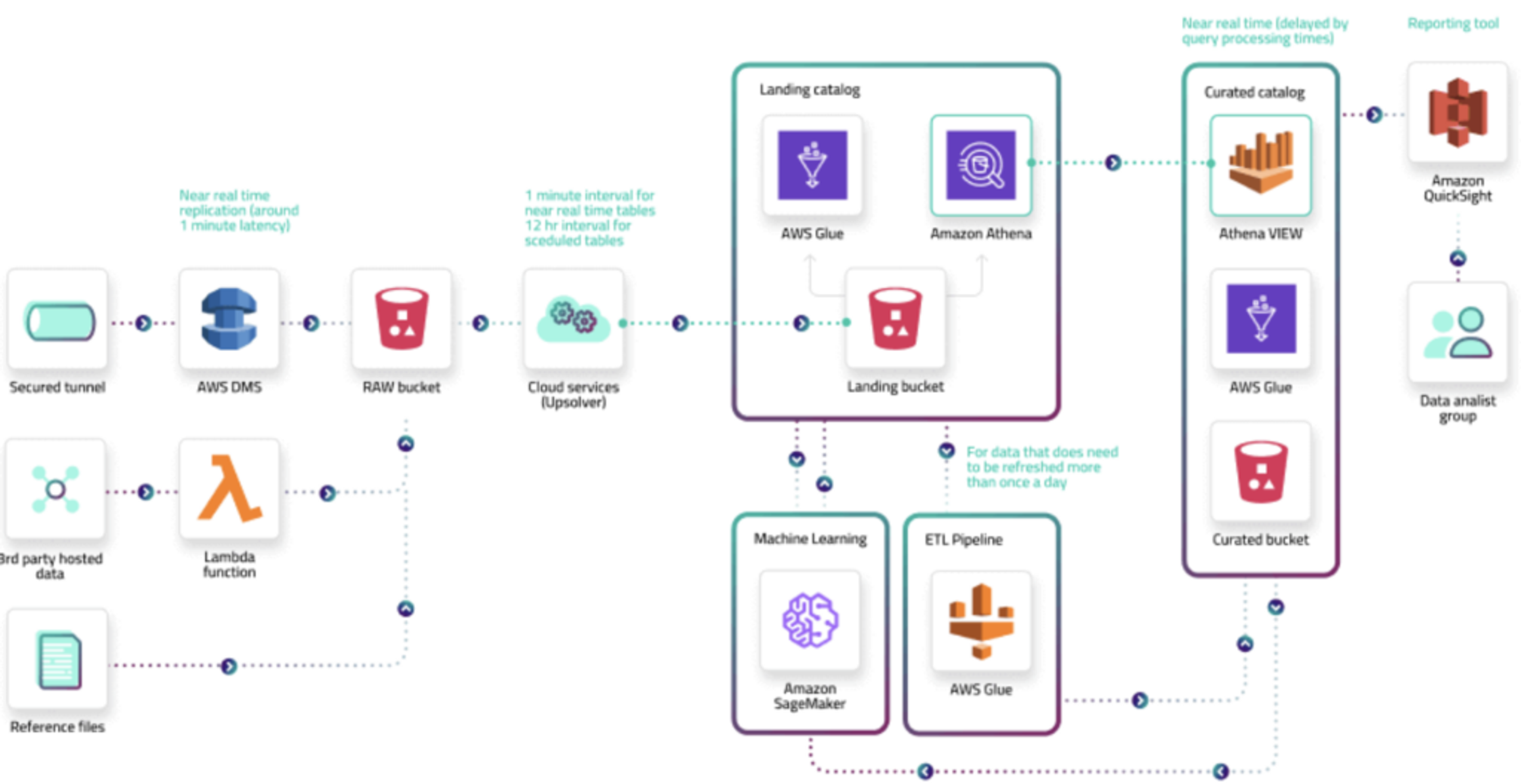
什么是数据管道?
Redis Blog
·
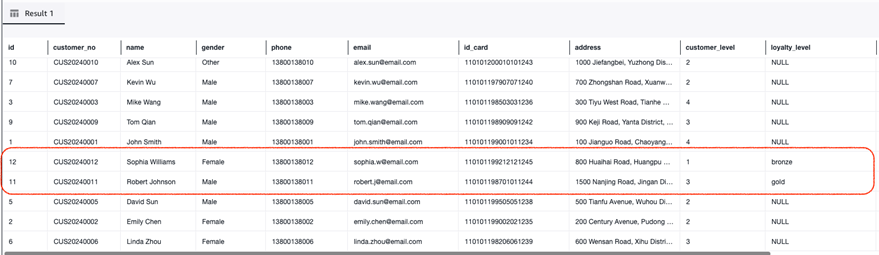
S3 Tables 实战:两种方案,把 MySQL 数据实时”搬”进 S3 Tables
亚马逊AWS官方博客
·
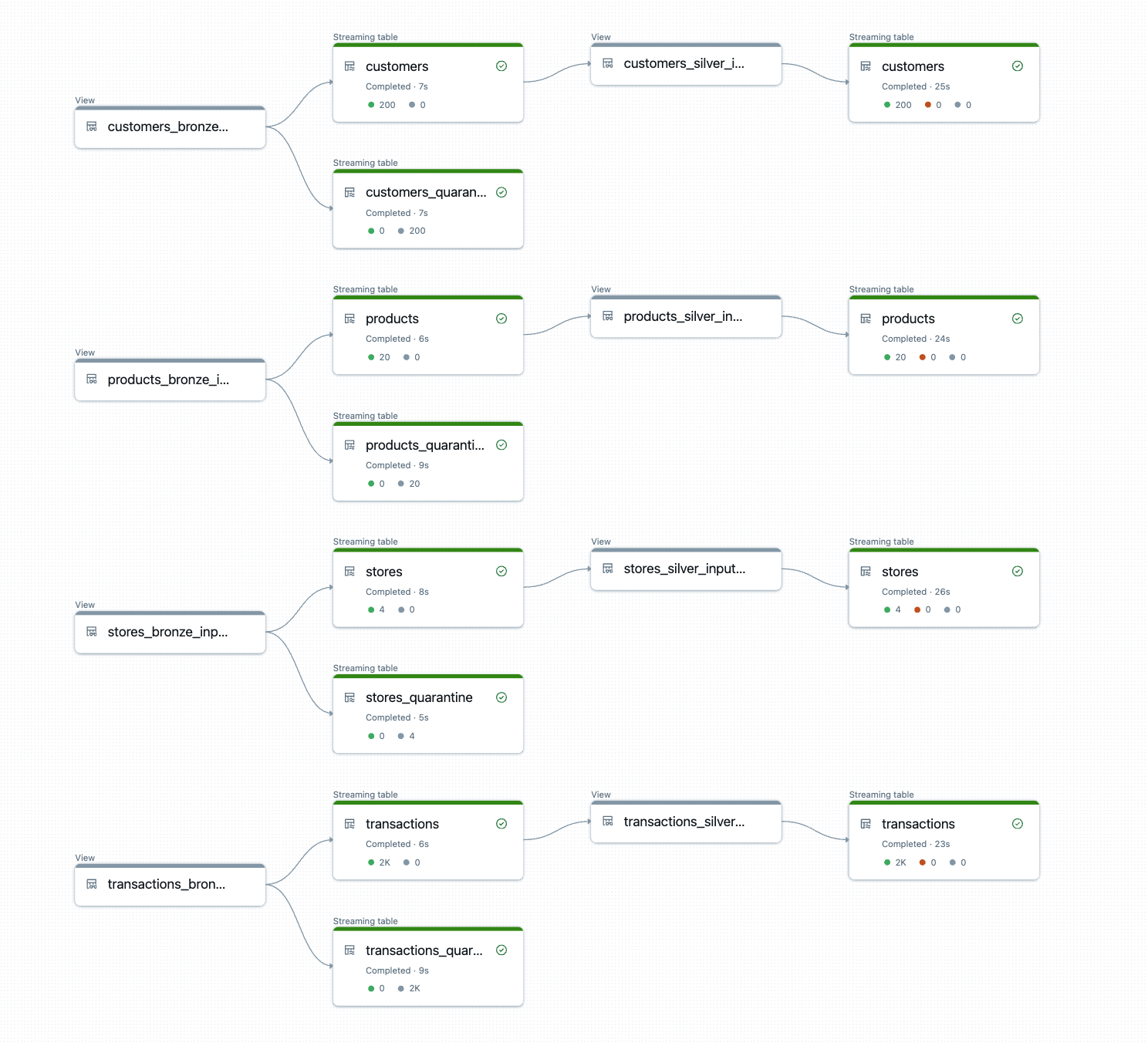
从混乱到规模:使用DLT-META对Spark声明式管道进行模板化
Databricks
·
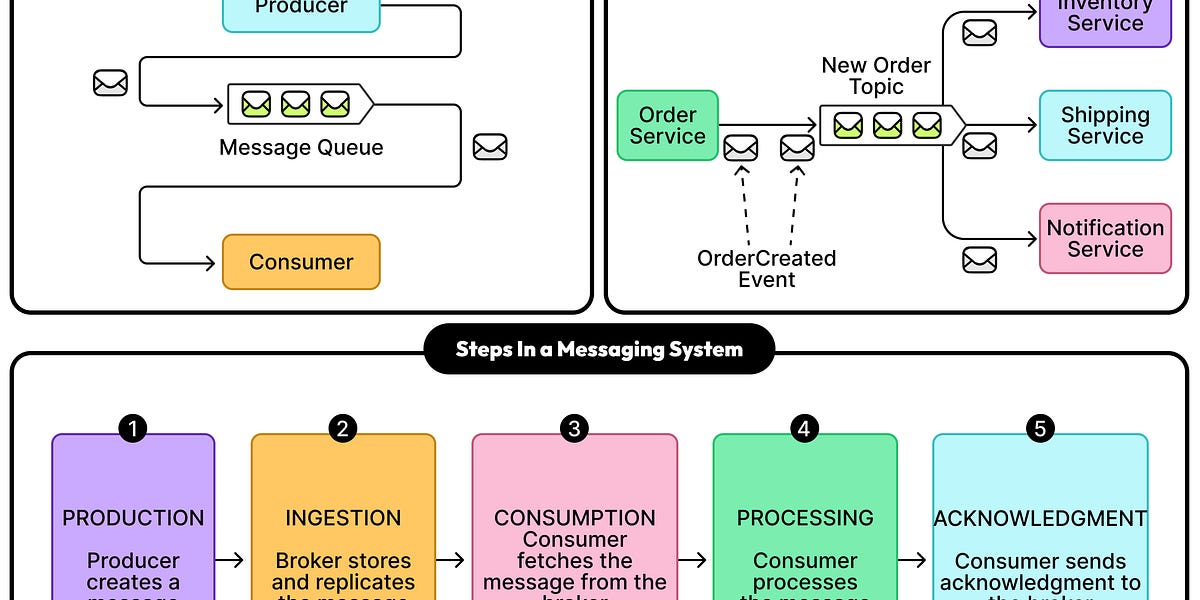
消息代理基础知识:存储、复制与交付保障
ByteByteGo Newsletter
·

重新定义批处理:工作流编排为何与流处理同样现代
BMC Software | Blogs
·



无盘运行Kafka的优势:如何在大规模环境中实现变革
The New Stack
·

基于华为开发者空间-云开发环境Docker+Flink实现大数据实时统计系统
华为云官方博客
·
