
从混乱到规模:使用DLT-META对Spark声明式管道进行模板化
内容提要
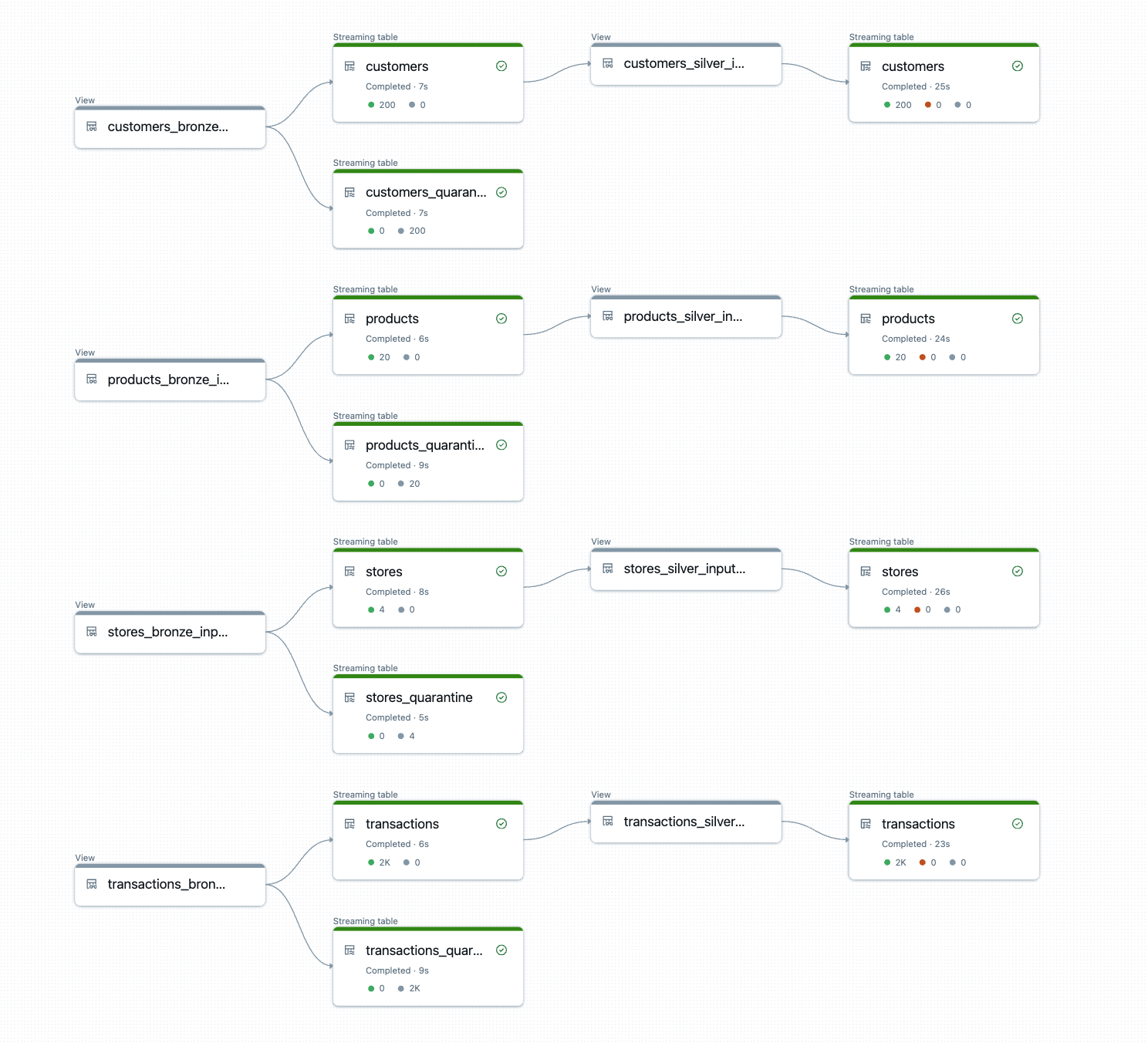
声明式管道通过意图驱动的方式构建批处理和流处理工作流,减少自定义代码,支持可重复的工程模式。随着数据使用的增长,管道数量增加,元编程通过结构化模板解决维护和一致性问题。DLT-META项目自动化管道创建,简化数据源添加和逻辑更新,提高开发效率和一致性。
关键要点
-
声明式管道通过意图驱动的方式构建批处理和流处理工作流,减少自定义代码,支持可重复的工程模式。
-
随着数据使用的增长,管道数量增加,元编程通过结构化模板解决维护和一致性问题。
-
DLT-META项目自动化管道创建,简化数据源添加和逻辑更新,提高开发效率和一致性。
-
手动管道在小规模下工作,但维护工作量随着数据增长而迅速增加,导致逻辑漂移和重复工作。
-
数据工程师面临的挑战包括每个数据源的工件过多、逻辑更新不传播、质量和治理不一致等。
-
DLT-META通过元数据驱动的元编程框架解决管道规模和一致性问题,自动化管道创建,标准化逻辑。
-
DLT-META集中管道逻辑于共享模板,减少重复和手动维护,便于快速扩展和新数据源的接入。
-
域团队可以通过配置安全地贡献,分析师和领域专家更新元数据,加速交付。
-
组织范围内的标准自动应用于所有管道,中央配置强制执行一致逻辑,支持合规性和操作要求。
延伸解读
元编程的优势
DLT-META通过元数据驱动的元编程框架,显著降低了数据管道的维护成本。随着数据源的增加,传统手动管道的复杂性和维护工作量迅速上升,而DLT-META则通过集中化的模板配置,确保逻辑的一致性和可扩展性,帮助团队更高效地管理数据流。
快速扩展与合规性
DLT-META的设计使得新数据源的接入变得更加迅速,团队只需更新元数据文件,便可自动将更改应用于所有相关管道。这种方法不仅提高了开发效率,还确保了企业范围内的标准和合规性,减少了因手动操作带来的错误风险。
领域团队的安全贡献
通过DLT-META,领域团队可以安全地通过配置贡献数据,分析师和领域专家能够直接更新元数据,加快交付速度。这种模式不仅提升了团队的灵活性,还确保了数据质量和治理标准的执行,避免了因逻辑漂移导致的潜在问题。
延伸问答
什么是声明式管道,它的主要优势是什么?
声明式管道通过意图驱动的方式构建批处理和流处理工作流,主要优势是减少自定义代码,支持可重复的工程模式。
DLT-META项目如何解决数据管道的规模和一致性问题?
DLT-META通过元数据驱动的元编程框架自动化管道创建,标准化逻辑,减少重复和手动维护,从而解决规模和一致性问题。
数据工程师在维护手动管道时面临哪些挑战?
数据工程师面临的挑战包括工件过多、逻辑更新不传播、质量和治理不一致等问题,导致维护工作量迅速增加。
DLT-META如何提高新数据源的接入速度?
DLT-META通过元数据驱动的更新,使得团队可以快速添加新数据源,修改业务规则,所有变更自动应用于下游工作负载,缩短接入时间。
使用DLT-META的管道逻辑是如何管理的?
DLT-META集中管道逻辑于共享模板,团队通过JSON或YAML定义规则,更新一次后逻辑自动传播到所有管道。
DLT-META如何支持组织范围内的一致性和合规性?
DLT-META通过中央配置强制执行一致逻辑,自动应用组织范围内的标准,支持合规性和操作要求。
