让每一份算力都变成有效Token
清华大学展示了搭载一念Unisonmind大脑的机器狗“哮天”,在无预设环境中完成走迷宫、称重和估水量等复杂任务。这次演示验证了物理通用人工智能的核心特征,即同一认知系统在不同实体上持续运行,形成实时的“感知—行动—反馈”闭环。
清华大学团队在ICML 26上获得杰出论文奖,提出了JustGRPO模型,解决了扩散语言模型(dLLM)在数学和编程推理中的灵活性陷阱问题。该模型在GSM8K基准测试中取得89.1%的准确率,展示了其推理潜力。
阿里巴巴与清华大学合作的论文《灵活性陷阱》入选ICML杰出论文,质疑扩散语言模型任意顺序生成的价值。研究表明,任意顺序生成会导致推理能力下降,提出的“JustGRPO”方法强制模型从左到右生成,显著提高推理效果。
研究团队提出了Spatial-TTT模型,旨在解决多模态模型在动态环境中持续更新空间记忆的问题。该模型通过在线更新机制,能够处理长达120分钟的视频流,显著提升空间智能表现。实验结果表明,Spatial-TTT在多个基准测试中超越现有模型,展现出更强的空间推理能力和效率,推动了流式视觉感知向持续世界状态建模的进展。
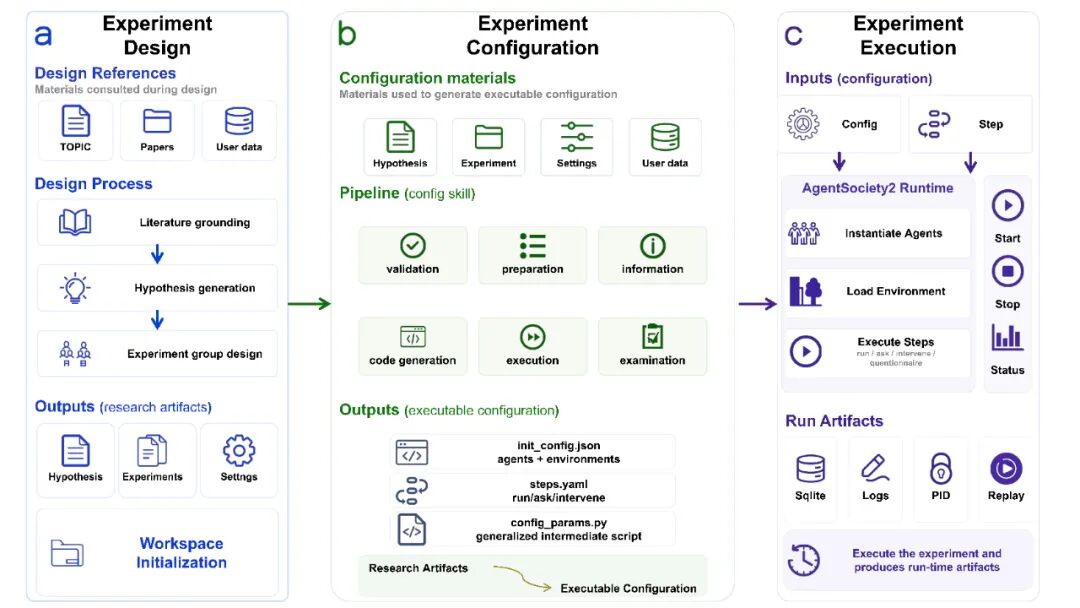
AgentSociety²旨在将AI与人类研究者协同工作,AI负责实验设计与数据分析,人类保留关键判断权,确保研究的社会意义。该平台整合文献、假设、实验与分析,提升社会科学研究的效率与可控性。
Noiz AI与香港科技大学、清华大学联合推出AudioX-Turbo音频生成模型,解决了生成速度慢和控制不精确的问题。该模型通过分布匹配蒸馏技术,将生成过程从50-200步缩减至4步,显著提升音质和实时生成能力。AudioX-Turbo的开源代码和数据集将推动音频生成技术的发展,应用于互动剧配音和实时音效等领域。
光象科技推出的Phi-Bot X1工业级自进化机器人,专注于制造业,具备高精度和高可靠性,能够在真实工厂环境中实现零失误作业。公司致力于提升生产力,未来计划将机器人技术扩展至更多制造领域。
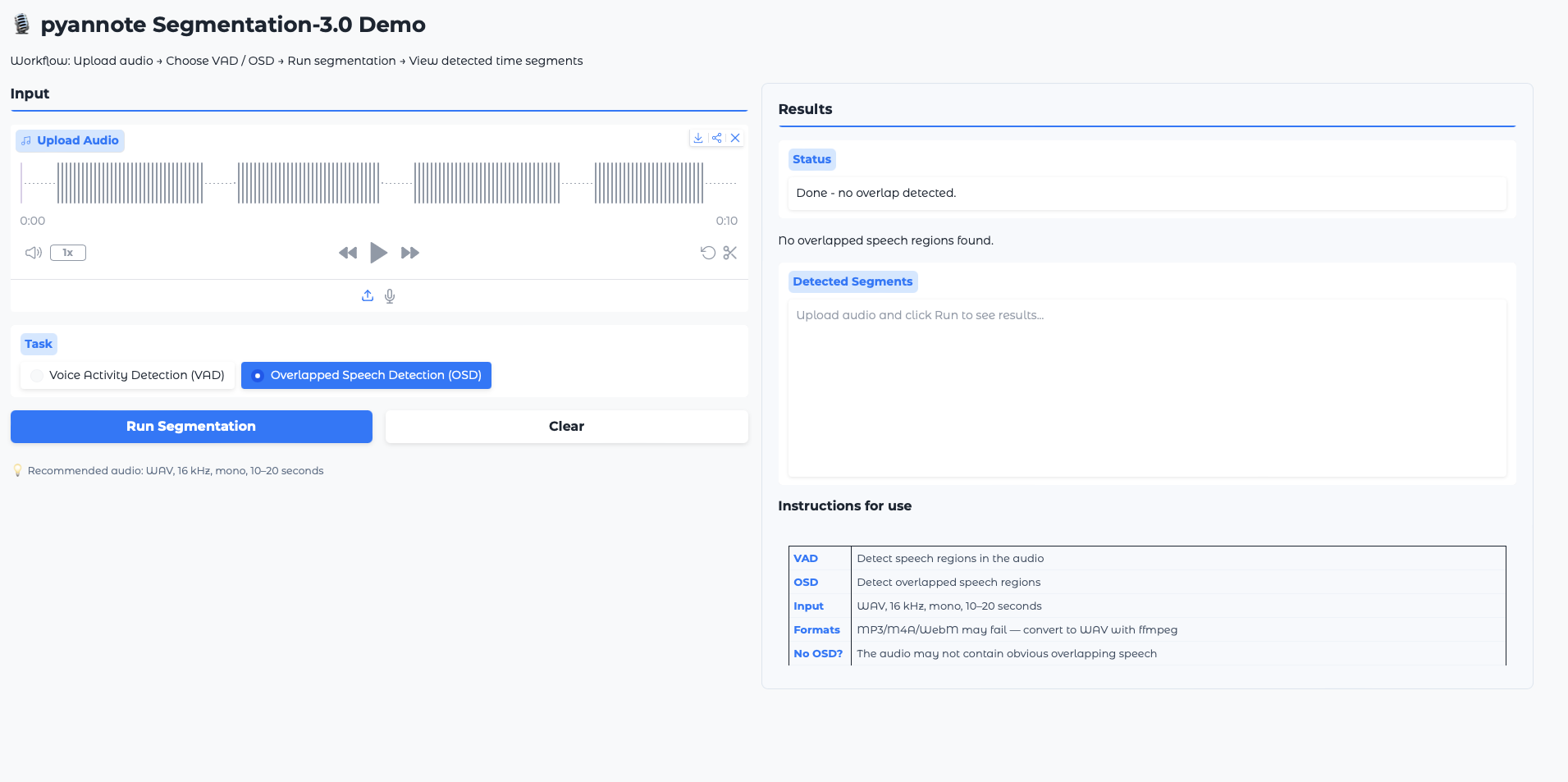
清华大学发布的《2026智能体安全研究报告》强调智能体安全的重要性,指出安全威胁包括输入、模型、输出、记忆和执行五大维度。报告提出了系统化的威胁模型和评测框架,并建议建立五层防御体系,最后提供了90天的实施路线图,以帮助企业安全部署智能体。
研究表明,睡眠中的记忆重激活影响睡眠动态,提供了“记忆-睡眠”双向作用的新证据。智源研究院与清华大学的研究发现,负向记忆再激活加剧睡眠碎片化,而正向记忆再激活增强睡眠连续性。这一发现为理解睡眠调控机制及相关精神疾病提供了新视角。
清华大学智能产业研究院推出了全新的机器人强化学习训练架构UniLab,打破了传统依赖GPU的训练模式。UniLab通过将仿真解耦到CPU侧,实现了更高的训练效率,并已开源,未来将扩展为通用的机器人学习研究平台。
Gamma-World是NVIDIA与多所高校合作开发的多智能体世界建模框架,旨在解决现有模型在多玩家场景中的局限性。通过单纯形编码和稀疏枢纽注意力的引入,Gamma-World实现了高效的身份表示和交互建模,支持实时生成和零样本泛化,显著提升了多智能体协作的仿真能力,适用于现实世界的多主体协作场景。
Gamma-World是NVIDIA与多所高校合作开发的多智能体世界建模框架,旨在解决现有模型在多玩家场景中的局限性。通过单纯形编码和稀疏枢纽注意力的引入,Gamma-World实现了高效的身份表示和跨智能体通信,显著提升了生成质量和实时性。该模型在多种任务中表现优异,展示了在真实物理场景中的广泛应用潜力。
是石科技成立于2021年,专注于通过并行优化技术提升国产AI算力效率,构建标准化、低成本的Token生产能力,解决算力资源碎片化问题。公司整合多种算力资源,优化推理过程,降低Token生产成本,提升吞吐量,推动中国AI产业的规模化和高质量发展。
黄仁勋将加入清华大学经济管理学院顾问委员会,该委员会由多位国际知名企业领袖组成,旨在提升学院的科研和教学水平。他近期还获得了第七个荣誉博士学位。
这篇文章讲述了作者27岁时的生活感悟与成长经历,回顾了在清华的学习、在字节的工作以及个人项目的进展。作者逐渐接受不确定性,珍惜与他人的情感联结,保持积极心态,强调在平凡日子中成长的重要性,鼓励继续探索人生旅程。
联邦学习中,平衡模型性能、数据隐私和通信开销是一大挑战。清华大学等研究团队提出了基于表征纠缠的框架FedRE,能够有效保护隐私并降低通信成本,同时适应模型异构场景。FedRE通过融合不同类别的表征生成纠缠表征,上传至服务器训练全局分类器,从而显著提升模型性能和隐私保护能力。
在2026年ICLR会议上,中国在全球AI领域表现突出,论文接收比例达到43.7%。清华大学以332篇论文位居全球第一,超越斯坦福和麻省理工。尽管中国在数量上领先,但美国在原创性论文方面仍占优势。研究员Nathan Lambert指出,中国实验室务实高效,团队合作良好,快速适应新技术,形成了强大的研发能力。
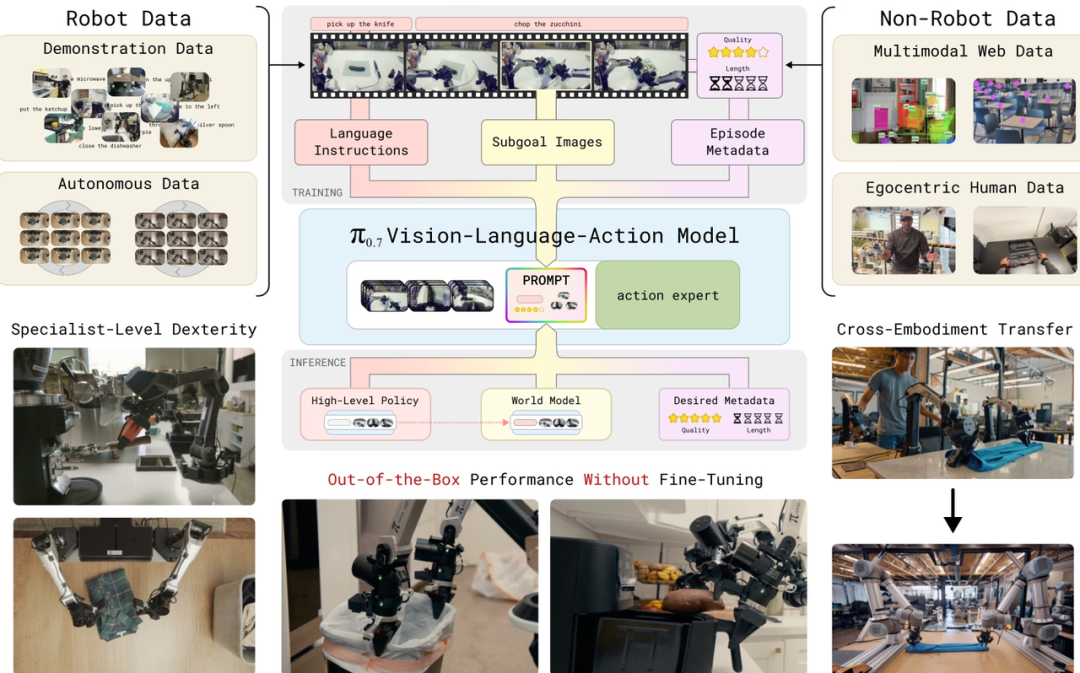
人工智能正从被动生成向具身智能转变,具身智能使机器能够在真实或虚拟环境中主动执行复杂任务。目前研究集中在统一物理语言、交互式世界模型和自主演化环境等方面,以推动通用人工智能的发展。HyperAI推荐了10篇相关论文,展示了具身智能在环境建模、任务执行和多智能体协作等领域的最新进展。
SRN-901是一种新型组合药物,通过调控mTOR、自噬、NAD+、炎症和代谢五个老化通路,在中年小鼠中实现了寿命延长33%和虚弱程度下降70%。该研究表明,抗衰老策略应从单一靶点转向系统性干预,标志着抗衰老研究进入组合疗法时代。
完成下面两步后,将自动完成登录并继续当前操作。