
论文汇总丨从「理解世界」到「进入世界」,NVIDIA/字节跳动/清华等团队引领的世界模型与VLA技术突破
内容提要
具身智能(Embodied AI)使智能体能够在物理和数字世界中学习与决策,关键技术为世界模型(World Model)。近期研究包括基于视频训练的机器人模型、开源世界模拟器和合成环境生成器,推动智能体在可生成环境中的进化。推荐的六篇论文展示了智能体在复杂任务中的应用与优化。
关键要点
-
具身智能(Embodied AI)使智能体能够在物理和数字世界中学习与决策。
-
世界模型(World Model)是支撑具身智能的关键技术,能够构建环境动态、预判未来状态、模拟行动结果。
-
研究包括基于视频训练的机器人模型、开源世界模拟器和合成环境生成器,推动智能体在可生成环境中的进化。
-
推荐的六篇论文展示了智能体在复杂任务中的应用与优化,涉及多个研究机构。
-
DREAMDojo是基于44,000小时第一人称视频训练的基础世界模型,支持实时、物理感知的机器人仿真。
-
LingBot-World是一个开源的世界模拟器,具备高保真度和实时交互能力。
-
Agent World Model(AWM)是一种合成环境生成器,支持可扩展的智能体训练。
-
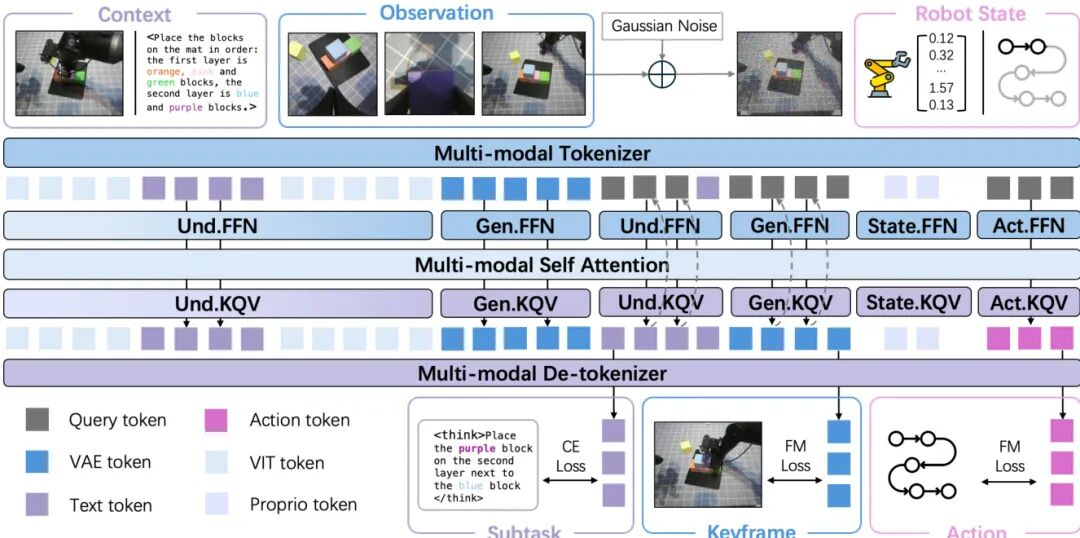
BagelVLA通过整合语言规划与视觉预测,实现精确的动作生成。
-
ACoT-VLA引入动作链式思维推理,提升了视觉-语言-动作模型的性能。
-
World-VLA-Loop通过闭环学习优化视频世界模型与VLA策略,提高了真实机器人任务的成功率。
延伸解读
具身智能的应用前景
具身智能的快速发展为机器人和智能体在复杂环境中的应用提供了新的可能性。通过世界模型,智能体能够在真实和虚拟环境中进行学习和决策,这将推动自动化、遥操作和智能制造等领域的进步。研究者们的努力使得智能体在多种任务中表现出更高的灵活性和适应性,未来可能会在更多行业中得到应用。
世界模型的技术挑战
尽管世界模型在具身智能中展现出巨大潜力,但仍面临一些技术挑战。例如,如何有效处理大规模数据集以提高模型的泛化能力,以及如何在复杂环境中保持实时交互的稳定性。这些问题的解决将直接影响智能体在实际应用中的表现,研究者们需要持续探索和优化相关算法。
闭环学习的重要性
闭环学习机制在智能体训练中至关重要。通过迭代失败反馈,智能体能够不断优化其策略和环境模型,从而提高任务成功率。这种方法不仅提升了模型的学习效率,也为未来的智能体开发提供了新的思路,尤其是在动态和不确定的环境中。
延伸问答
什么是具身智能,它的主要功能是什么?
具身智能(Embodied AI)使智能体能够在物理和数字世界中学习与决策。
世界模型在具身智能中起什么作用?
世界模型(World Model)能够构建环境动态、预判未来状态、模拟行动结果,是支撑具身智能的关键技术。
DREAMDojo是什么,它的主要特点是什么?
DREAMDojo是基于44,000小时第一人称视频训练的世界模型,支持实时、物理感知的机器人仿真,适用于开放世界任务。
LingBot-World的功能和优势是什么?
LingBot-World是一个开源的世界模拟器,具备高保真度、实时交互能力和长期记忆能力,支持多种环境场景。
BagelVLA如何提升动作生成的精确性?
BagelVLA通过整合语言规划与视觉预测,实现精确、低延迟的动作生成,在复杂多阶段操作任务中显著优于基线方法。
World-VLA-Loop的闭环学习机制有什么优势?
World-VLA-Loop通过迭代失败反馈共同优化视频世界模型与VLA策略,使真实机器人任务的成功率提升36.7%。
