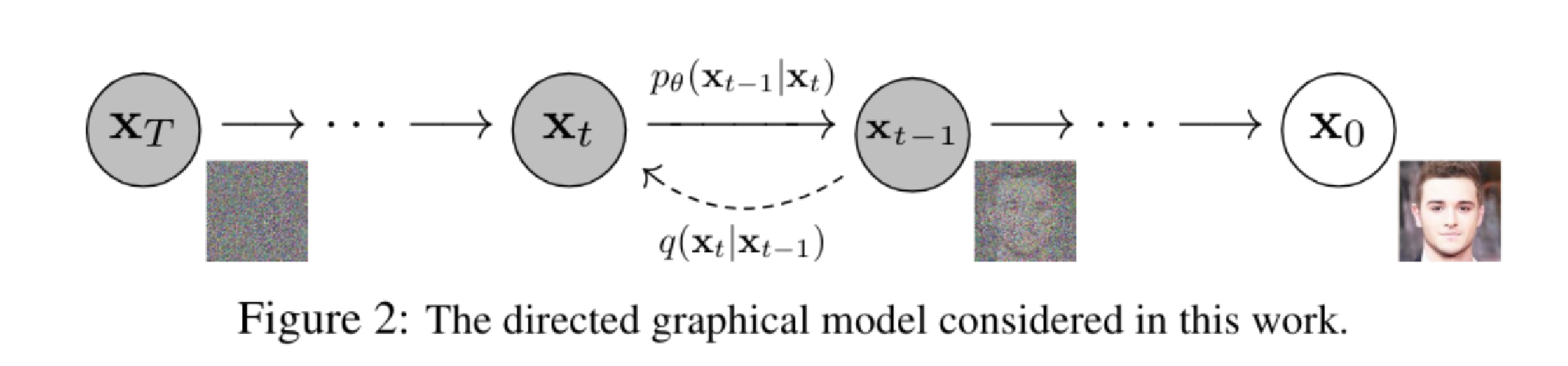
DDPM(去噪扩散概率模型)通过逐步添加噪声生成图像,利用神经网络预测并去除噪声。模型依赖高斯分布,损失函数使用均方误差(MSE)衡量真实噪声与预测噪声的差异。训练过程中,模型优化以提升生成图像质量,最终通过积分将预测的高斯分布转化为清晰图像。
S²-Guidance方法通过随机丢弃网络模块,实现AI自我修正,显著提升生成图像和视频的质量与连贯性,简化了传统方法的调参过程。
扩散模型是一种生成图像的AI算法,通过逐步添加和去除噪声来生成新图像。它包括前向过程(将图像转为噪声)和反向过程(从噪声重建图像)。DALL-E和Midjourney等产品利用文本提示指导生成,采用不同技术实现。
本研究提出了一种互联网增强文本到图像生成(IA-T2I)框架,旨在改善现有模型在处理不确定知识文本提示时的不足。该框架通过参考图像和主动检索等机制,提高了生成图像的准确性和相关性,实验结果显示其性能优于现有模型,特别是在不确定知识处理上提升了约30%。
本文介绍无服务器架构及其优势,强调开发者可专注于应用代码,无需管理服务器。通过Nitric框架和OpenAI的DALL-E模型,读者将学习构建生成图像的应用程序及相关开发环境和部署步骤。
本文介绍了如何通过 WebUI-Forge 一键包加载 Flux.1.dev 模型生成图像。步骤包括下载一键包和模型、运行启动脚本、选择模型、设置生成参数并生成图像。用户可以调整参数以获得不同效果,并保存生成的图像。
本研究提出递归扩散概率模型(RDPM),旨在解决扩散概率模型与大语言模型在生成图像和文本方面的差异。RDPM通过递归令牌预测机制增强了扩散过程,展现出优越的性能,尤其在推理速度上具有明显优势。
本研究系统调查了人工智能生成图像与自然图像之间的差异,提出了评估基准和包含44万个样本的多模态数据集DNAI。结果显示在多个维度上存在显著差异,强调结合定量指标与人类判断以全面理解AI生成图像质量的重要性。
本研究提出了图像再生任务,以解决文本到图像模型评估中的信息不对称问题。通过ImageRepainter框架和多样化数据集,显著提升了生成图像的质量和模型性能。
本研究探讨去噪扩散概率模型(DDPMs)在生成图像时潜在空间的不足,分析高斯噪声与生成样本的关系,指出反演技术的局限性,并证明生成图像的高层特征在训练中迅速稳定,为优化图像生成模型提供了重要见解。
本研究提出了AttnMod模型,旨在帮助艺术家在生成图像中强调特定特征或风格。该模型通过修改跨注意力机制,在去噪扩散过程中创造出不依赖文本提示的新艺术风格,展现了重要的艺术创作潜力。
本文提出了多种新方法以提升生成图像质量,包括模糊引导、高级自注意引导和无分割引导等。这些方法在无条件和条件生成任务中表现优越,显著提高了扩散模型的性能,并探讨了自适应引导和损失指导的影响,提出了有效的优化策略。
本文探讨了生成图像质量评估指标,指出FID和IS存在偏差,提出了新的CMMD和SID指标,以更可靠地评估图像生成模型的性能。研究表明,这些新指标能有效提高评估准确性,推动图像生成技术的发展。
本文探讨了扩散模型在生成视觉数据中的应用,提出了Diffusion Alignment with GFlowNet(DAG)算法,以提高生成图像的质量和与文本描述的对齐。实验结果表明,该方法有效解决了传统模型在生成过程中的低质量和重复性问题,满足了自然语言处理领域对一致性和可控文本生成的需求。
最近的文本到图像扩散模型在生成高质量图像方面取得了显著进展,但在提示语义遵循上仍存在困难。为此,提出了一种无需训练的方法,通过监控概念引导轨迹来改善模型的语义对齐。实验结果表明,该方法有效提升了生成图像与文本描述的一致性。
本文介绍了多种变分自编码器(VAE)架构的进展,包括高效脉冲变分自动编码器(ESVAE)和结合潜在变量模型的pi-VAE。这些模型在生成图像和分析神经元响应数据方面表现优越,成功解决了潜变量坍塌问题,并在多个数据集上验证了其有效性。
本文探讨了生成图像的多种方法,包括利用空间特征和自我关注进行微调的技术。研究提出了StableRep和DSD等新方法,展示了在少样本学习和图文匹配中的优越性能。此外,ControlNet和BLIP-Diffusion模型支持多模态控制,提升了图像生成的效率和灵活性,并探讨了强化学习在扩散模型中的应用,以提高生成样本的多样性和符合人类偏好。
本研究探讨了扩散模型中引导信息对性能的影响,提出了新损失函数和无分类器的引导方法,以提高样本质量和生成图像的控制力。实验结果表明,改进的指导方法在生成图像的质量和多样性方面有效。
本文探讨了多种牙齿分割技术,包括弱监督方法、3D变换器架构和基于生成图像的框架,旨在提高牙齿分割的精度和效率,强调其在牙科应用中的临床适用性和成本效益。
本研究提出了一种高效的量化方法,优化了扩散模型的性能,显著提高了生成图像的质量。通过引入量化感知训练和新基准QDiffBench,解决了低位量化对模型性能的影响,实现了在低位宽下的高效推断。实验结果表明,该方法在保持性能的同时,提升了生成速度和准确性。
完成下面两步后,将自动完成登录并继续当前操作。