




何恺明首个语言模型:不走GPT老路,105M参数干翻主流
dotNET跨平台
·

推测解码:工作原理、应用场景及其在推理架构中的位置
Redis Blog
·
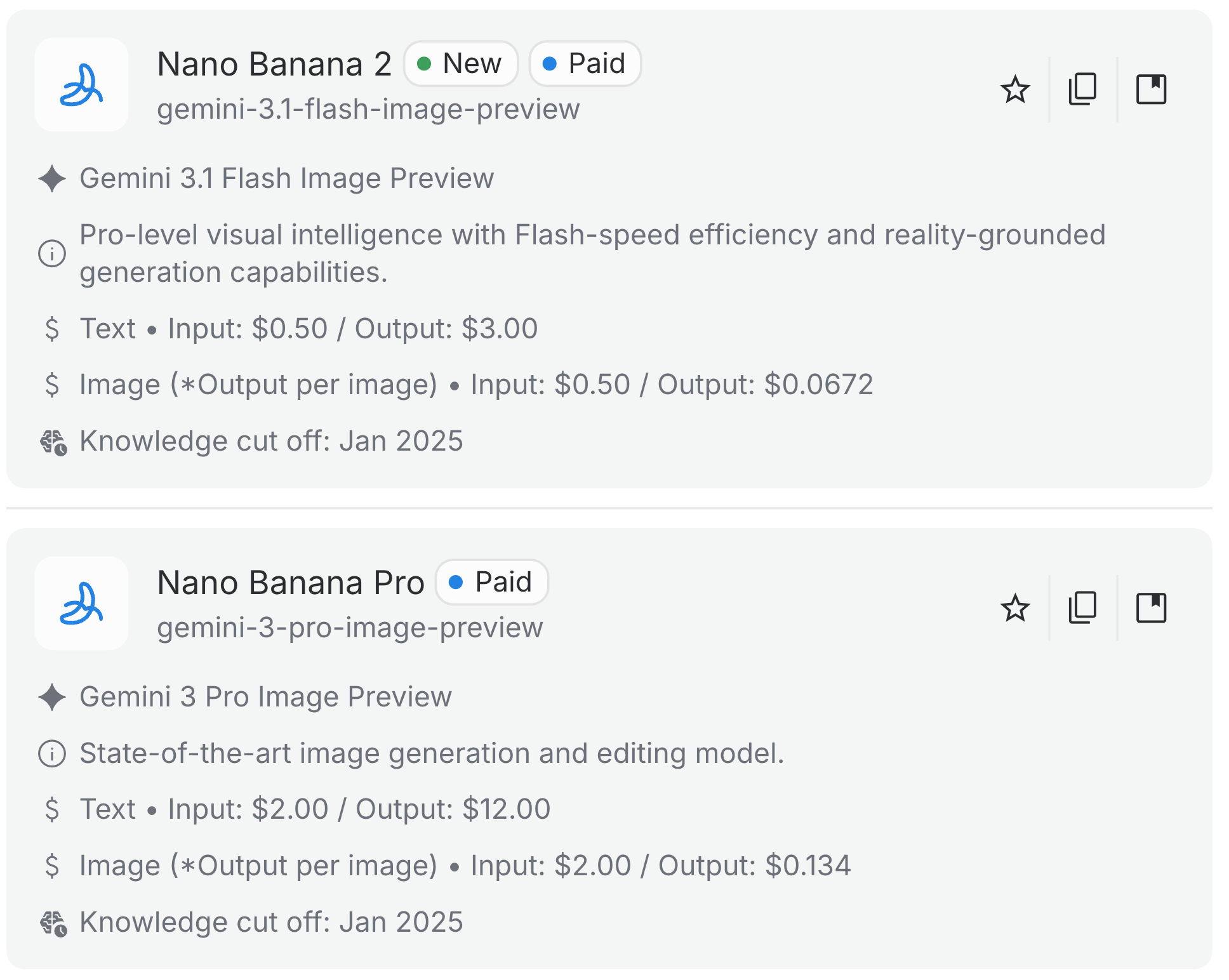

使用扩散生成文本(以及使用LLMs的投资回报)
Stack Overflow Blog
·



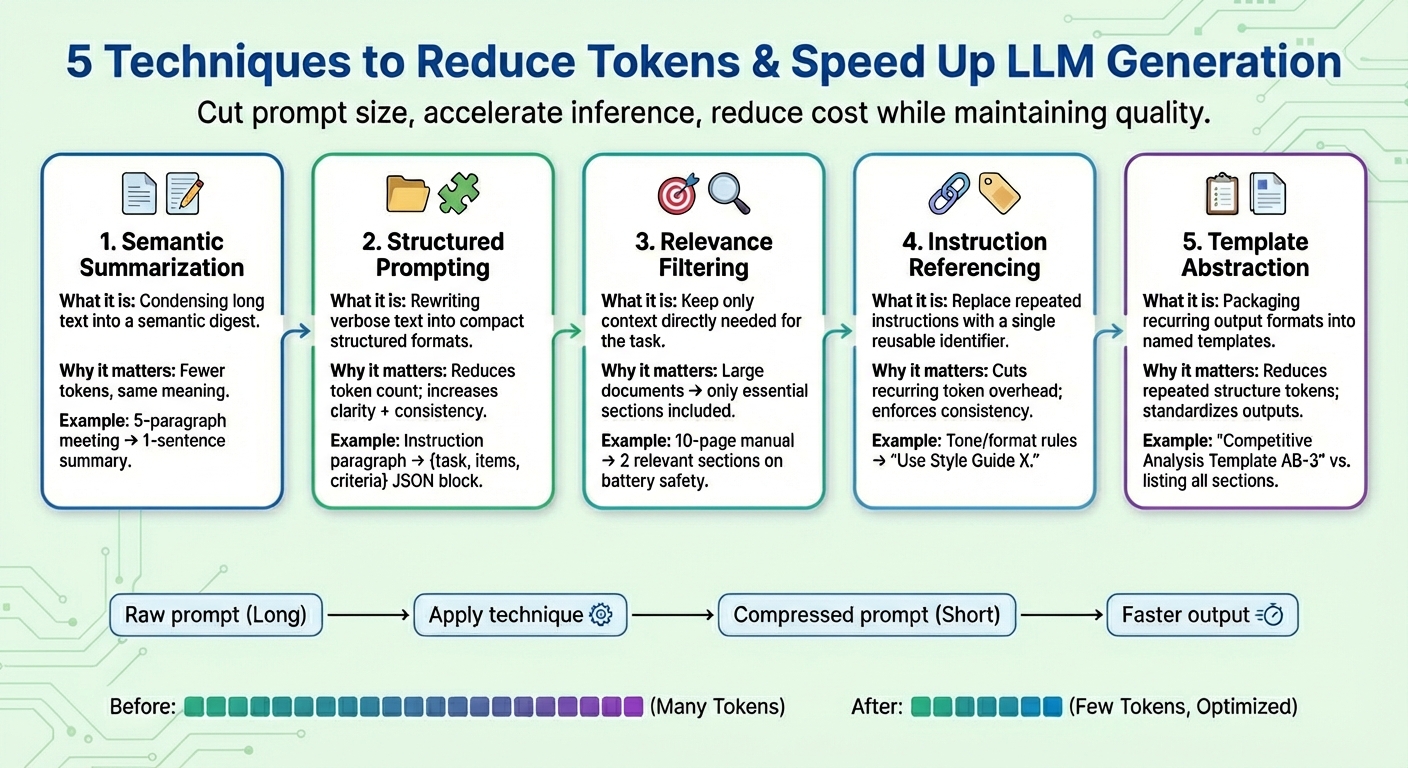
大型语言模型生成优化与成本降低的提示压缩
MachineLearningMastery.com
·
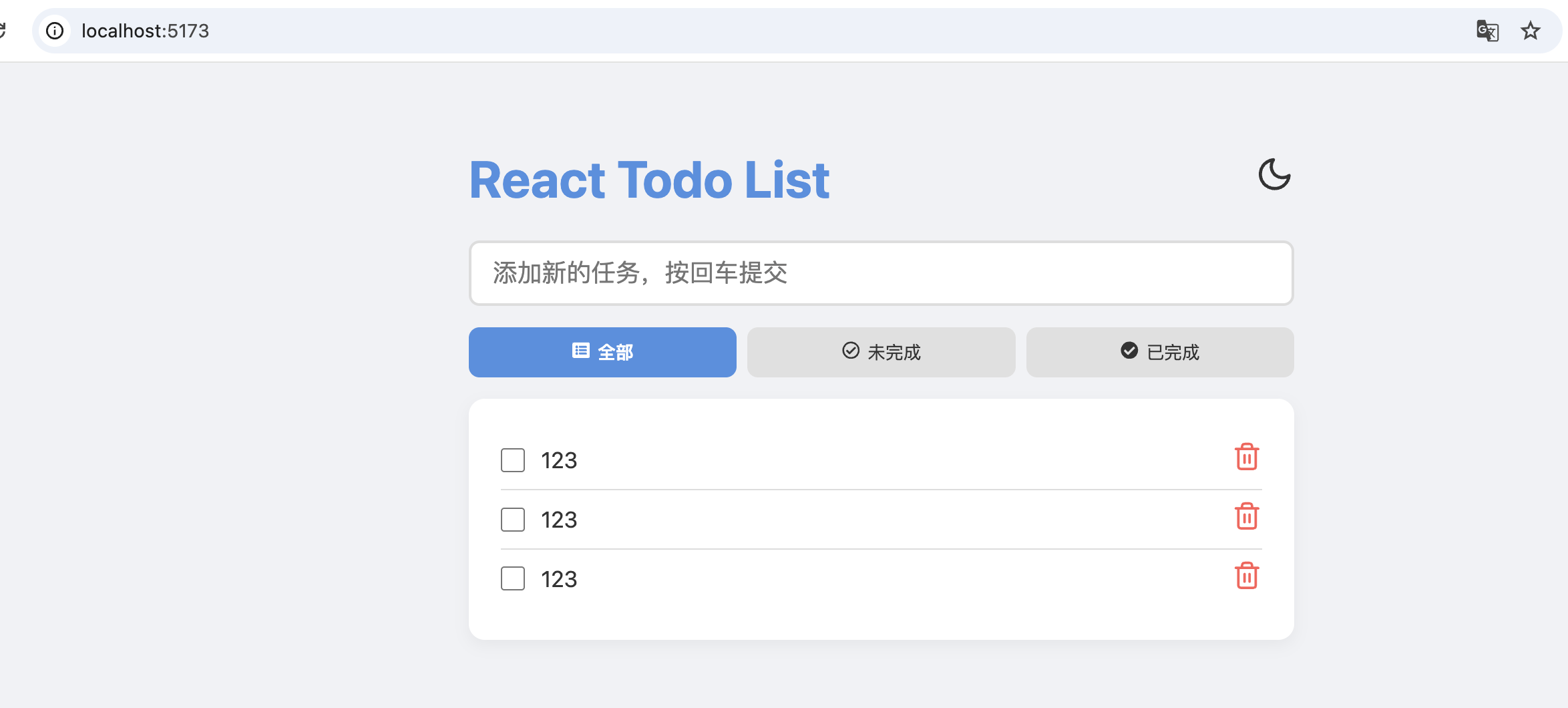
来看下我装备了5060TI显卡的gpt-oss模型表现
Nicksxs's Blog
·

你的语言模型预知未来:揭示其多标记预测潜力
Apple Machine Learning Research
·
