
大型语言模型生成优化与成本降低的提示压缩
内容提要
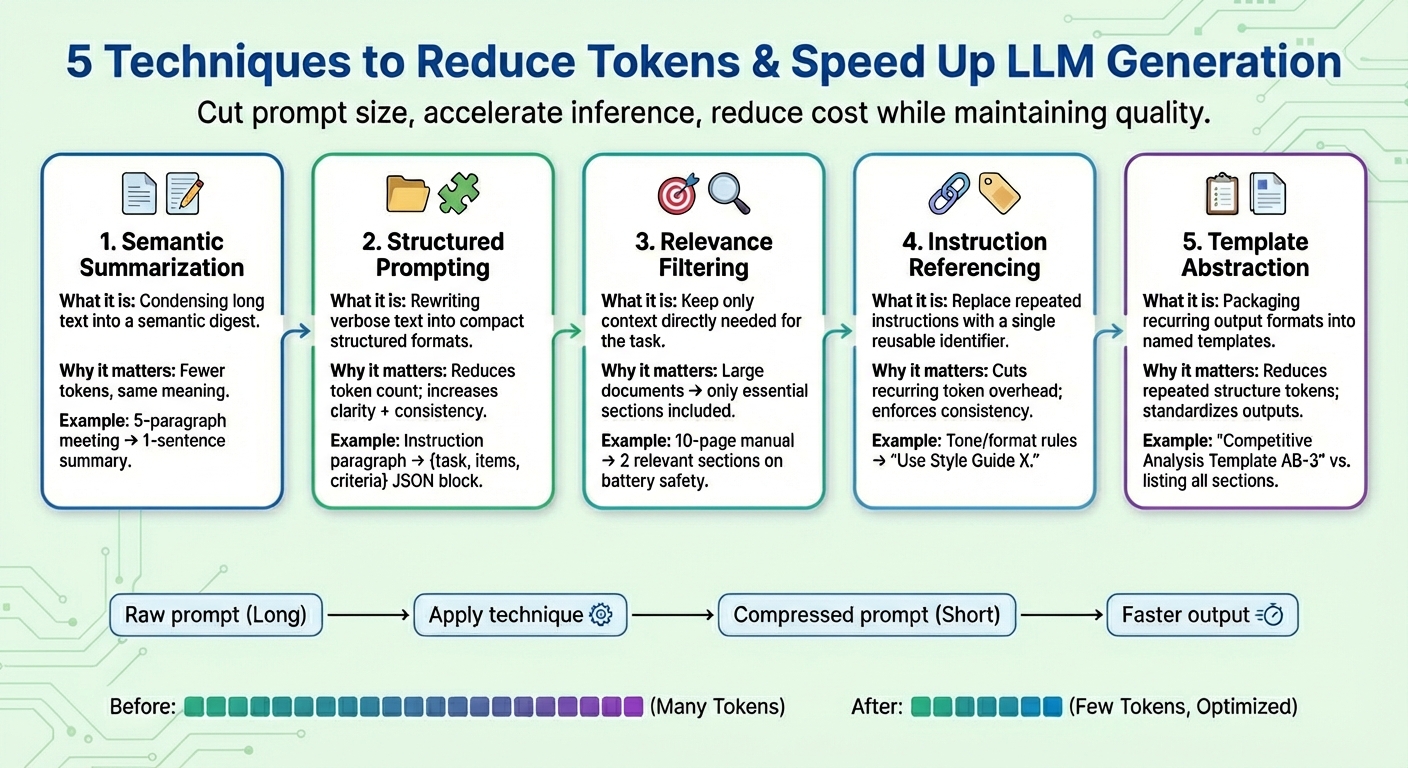
本文介绍了五种提示压缩技术,以减少大型语言模型(LLM)的令牌数量,提升生成速度和任务质量。这些技术包括语义摘要、结构化提示、相关性过滤、指令引用和模板抽象,旨在提高模型效率和一致性,降低计算成本。
关键要点
-
本文介绍了五种提示压缩技术,以减少大型语言模型(LLM)的令牌数量,提升生成速度和任务质量。
-
提示压缩技术旨在降低计算成本,同时保持任务结果的质量。
-
第一种技术是语义摘要,通过提炼长内容为简洁版本,减少输入令牌数量。
-
第二种技术是结构化提示,使用半结构化格式(如JSON)来表达信息,减少令牌数量并提高模型一致性。
-
第三种技术是相关性过滤,仅保留与任务相关的文本部分,从而减少提示大小。
-
第四种技术是指令引用,将常见指令注册为单一标识符,减少重复并保持任务一致性。
-
第五种技术是模板抽象,将常见模式封装在模板名称下,减少重复令牌并保持提示清晰。
-
这些技术有助于加快LLM生成速度,解决因提示过载导致的性能下降问题。
延伸解读
提示压缩的必要性
随着大型语言模型(LLM)应用的普及,用户输入的提示往往变得冗长复杂,导致生成速度下降。提示压缩技术的出现,正是为了应对这一挑战,通过减少令牌数量来提高生成效率,降低计算成本。理解这些技术的应用场景,可以帮助用户更有效地利用LLM。
技术比较与选择
本文介绍的五种提示压缩技术各有侧重,用户可以根据具体需求选择合适的方法。例如,语义摘要适合处理长文本,而结构化提示则更适合需要清晰格式的任务。了解每种技术的特点,有助于在不同场景中优化LLM的使用效果。
潜在风险与限制
尽管提示压缩技术能够提高生成速度,但在某些情况下,过度压缩可能导致信息丢失或上下文理解不准确。因此,在应用这些技术时,用户需谨慎评估压缩程度,以确保生成结果的质量不受影响。
延伸问答
什么是提示压缩技术?
提示压缩技术是用于减少大型语言模型(LLM)输入令牌数量的技术,旨在提高生成速度和任务质量,同时降低计算成本。
语义摘要如何帮助减少令牌数量?
语义摘要通过提炼长内容为简洁版本,减少输入令牌数量,从而加快生成速度。
结构化提示的优势是什么?
结构化提示使用半结构化格式(如JSON)表达信息,减少令牌数量,提高模型一致性和减少歧义。
相关性过滤是如何工作的?
相关性过滤仅保留与任务相关的文本部分,从而减少提示大小,提高模型的专注度和预测准确性。
指令引用如何提高任务一致性?
指令引用将常见指令注册为单一标识符,减少重复并保持任务一致性。
模板抽象的应用场景是什么?
模板抽象用于封装常见模式,将其命名为模板,以减少重复令牌并保持提示清晰。
